
Abstract
Sequencing-based genetic tests to identify individuals at increased risk of hereditary breast and ovarian cancers have resulted in the identification of more than 40,000 sequence variants of BRCA1 and BRCA2. A majority of these variants are considered to be variants of uncertain significance (VUS) because their impact on disease risk remains unknown, largely due to lack of sufficient familial linkage and epidemiological data. Several assays have been developed to examine the effect of VUS on protein function, which can be used to assess their impact on cancer susceptibility. In this study, we report the functional characterization of 88 BRCA2 variants, including several previously uncharacterized variants, using a well-established mouse embryonic stem cell (mESC)-based assay. We have examined their ability to rescue the lethality of Brca2 null mESC as well as sensitivity to six DNA damaging agents including ionizing radiation and a PARP inhibitor. We have also examined the impact of BRCA2 variants on splicing. In addition, we have developed a computational model to determine the probability of impact on function of the variants that can be used for risk assessment. In contrast to the previous VarCall models that are based on a single functional assay, we have developed a new platform to analyze the data from multiple functional assays separately and in combination. We have validated our VarCall models using 12 known pathogenic and 10 neutral variants and demonstrated their usefulness in determining the pathogenicity of BRCA2 variants that are listed as VUS or as variants with conflicting functional interpretation.
Similar content being viewed by others

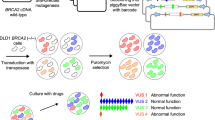
Introduction
Breast cancer is one of the most frequently diagnosed malignancies in the world. As per GLOBOCAN 2018 estimates, the number of new cases world-wide exceeded 2.08 million and there were more than 600,000 deaths1. In the United States, breast cancer associated mortality has been declining gradually since 2001 due to improved treatment options and availability of cancer screening tools (https://seer.cancer.gov/csr/1975_2014/)2. In addition to mammogram-based screening, there is a marked increase in sequencing-based genetic tests to identify individuals at risk of developing the hereditary form of the disease. Mutations in BRCA1 and BRCA2 are known to significantly increase the risk of hereditary breast and ovarian cancer (HBOC) (https://seer.cancer.gov/csr/1975_2014/)2. Risk of other cancers such as prostate and pancreatic cancers are also increased in BRCA2 mutation carriers3,4,5,6,7.
Sequencing-based genetic tests to screen for mutations in BRCA1 and BRCA2 are recommended to individuals with a personal or family history of early onset and/or bilateral breast and/or ovarian cancer, or a history of male breast cancer. Sequencing of BRCA1 and BRCA2 has resulted in the identification of more than 21,000 variants that are listed in ClinVar (https://www.ncbi.nlm.nih.gov/clinvar/). Recent efforts to have a more reliable and accessible record of variants resulted in the establishment of BRCA Exchange (https://brcaexchange.org/) by the Global Alliance for Genomics and Health (GA4GH)8. BRCA Exchange has combined the information from ClinVar, the Breast Cancer Information Core (https://research.nhgri.nih.gov/projects/bic/index.shtml) and Leiden Open Variant Database (https://www.lovd.nl/) as well as a number of population databases making it the largest open source of information on BRCA variants. Currently, BRCA Exchange lists 40,331 unique BRCA variants.
Determining the functional consequence of variants that result in a single amino acid change or small in-frame deletion or insertion is challenging and a major hurdle in their risk assessment. A number of in silico models have been generated to aid in predicting the impact of amino acid change on protein function9,10,11,12,13. Epidemiological studies provide the most reliable information to classify the variants as neutral or deleterious based on co-occurrence in trans with a known deleterious variant, detailed analysis of personal and family history of cancer in probands and co-segregation of the variant with the disease in families. Because most variants are rare, very limited, if any, epidemiological data is available for them and they remain unclassified and are referred to as variants of unknown clinical significance or VUS. To date, more than 2800 BRCA1 and 5000 BRCA2 variants are reported as VUSs in ClinVar. In BRCA Exchange, only 7445 variants out of more than 40,000 variants, are classified by the Evidence Based Network for the Interpretation of Germline Mutant Alleles (ENIGMA) expert panel14.
In recent years, the value of functional assays in determining the impact of VUS on BRCA1 or BRCA2 function has been widely recognized. Significant effort has been devoted to developing assays that have high specificity and sensitivity. Such assays include those that examine the BRCA1 transcriptional activity, or functional complementation assays in BRCA1-deficient or BRCA2-deficient hamster or human cancer lines15,16. A CRISPR–Cas9-based high throughput approach of saturation genome editing has been utilized to examine the effect of BRCA1 variants in HAP-1 cells, a haploid human cell line17. More recently, BRCA2 variants were expressed in BRCA2-deficent DLD1 cells and their response to multiple PARP inhibitors (PARPi) was used to functionally classify them18. We and others have utilized mouse embryonic stem cells (mESC) as a model system for functional evaluation of BRCA1/2 VUS based on the observation that both genes are essential to the viability of mESC19,20,21,22,23,24,25,26,27,28.
A standardized five tier classification system is used to classify variants based on their likelihood of pathogenicity29. As per the American College of Medical Genetics and Genomic (ACMG) guidelines and the recommendations of the International Agency for Research on Cancer (IARC), class 1 and 2 designations are used for variants that are “not pathogenic” or “likely to be not pathogenic”, respectively and 4 and 5 for variants that are “likely pathogenic” and “definitely pathogenic”, respectively. Variants whose functional significance remains uncertain are class 3 variants (http://www.lovd.nl). Based on the recommendations of ENIGMA and ACMG, variants evaluated by a functional assay should be classified based on their impact on function. As per the guidelines, variants are classified as “functionally normal” or “functionally abnormal” based on the results of any functional assay30,31. “Functionally abnormal” variants can be further characterized as complete loss-of-function, partial loss-of-function/intermediate effect/hypomorphic, gain-of-function, dominant-negative30. In this study, we have followed these guidelines for functional characterization of variants evaluated by our mESC-based functional assay.
The ultimate goal of any functional assay is to obtain reliable information on the impact of the VUS on the tumor suppressor function. However, the results of most functional assays are not binary. Due to experimental variabilities and the hypomorphic nature of several VUS, the measured functional activity spans a range of values between the positive (wild type (WT)) and negative controls. This makes it challenging to classify variants using the results of functional assays. To address this, computational approaches are being utilized to deduce the pathogenicity of VUS. The Bayesian hierarchical model referred to as VarCall was first utilized to classify BRCA1 VUS using the results of an in vitro transcriptional activation assay32. A similar approach was subsequently described for classification of BRCA2 VUS using a homology directed DNA repair assay33.
In this study, we have developed a VarCall model for predicting the probabilities of impact on function (PIF) of BRCA2 VUS using the results obtained from our mESC-based functional assays. In this assay, variants are generated in a bacterial artificial chromosome (BAC) clone containing full-length human BRCA2 by recombineering and their impact on cell survival and sensitivity to DNA damaging agents is examined in mESC lacking endogenous Brca219,20,21,22,23,24 (Fig. 1a). Variants that partially or fully rescue the lethality of Brca2KO/KO ES cells and are functionally indistinguishable from WT are considered to be neutral or “functionally normal”. In contrast, variants are considered to be hypomorphic if they rescue the lethality of Brca2KO/KO ES cells but are not fully proficient in one or more functions (Fig. 1a). Our computational model combines the impact of the VUS on cell viability with their sensitivity to six different DNA damaging agents to calculate the PIF. We have used our VarCall model to estimate the PIF of 88 BRCA2 variants distributed across the length of the protein, including 24 that are listed as VUS in the ClinVar database. We have also examined 26 variants that have conflicting classification data in ClinVar including at least one report classifying them as a VUS. We have further validated the model by examining an additional 25 variants that were previously functionally characterized by our mESC-based functional assay23,24.

a Schematic representation of the functional assay. BAC DNA encoding human BRCA2 gene with any variant was introduced into PL2F7 mES cells containing a conditional allele and a knockout allele of Brca2. Conditional allele was further deleted by CRE and the recombinants were selected on HAT containing media. Depending on the impact of BRCA2 variants, HATr cells may or may not be viable. Viable HATr cells were further tested for sensitivity to different DNA damaging agents to distinguish between variants that have no impact on function and those that have some loss of function (hypomorphic). Star in the BAC construct represents variant. Two halves of HPRT mini gene are marked in solid boxes as HP and RT. Solid arrows denote loxP sites. b Schematic diagram of BRCA2 protein with different domains and position of variants selected. Different domains are marked as colored boxes and the amino acids (aa) for the respective domains are noted below. HD helical domain, DBD DNA-binding domain, OB oligonucleotide binding fold, TR2 C-terminal RAD51-binding site, NLS nuclear localization signal15,43,44. Variants selected for analysis are denoted as colored solid circles on top. Missense, silent or synonymous and nonsense variants are marked in red, blue, and black colors, respectively.
Results
Functional analysis of variants: impact on viability of Brca2KO/KO ES cells
We selected 88 variants for analysis in this study, each based on one or more of the following criteria: (i) the variant was listed as “uncertain” in ClinVar or class 3 in IARC classification; (ii) the variant was observed in Fanconi anemia (FA) patients; (iii) the variant may have an effect on splicing based on proximity to an exon–intron junction; (iv) truncating variants. Forty-seven variants are located in the DNA-binding domain (Fig. 1b). Twenty-four variants are listed as “uncertain” and twenty-six variants as having “conflicting interpretation” in ClinVar. Five variants are listed as class 3 in the IARC classification. Thirteen variants are located in close proximity to an exon-intron junction (within +3 or −3 from a splice junction site) (Supplementary Table 1). We included ten variants with previous classifications in the ClinVar database or based on published functional assay data for purposes of evaluating our assays and classification models. These were P168T, F1524V, G1529R, D2312V, K2411T (benign) and Q742X, E1308X, L2740X, C3069X, D3073G (pathogenic, Supplementary Table 1)20,34,35. In addition to these ten previously classified variants, we included V220Ifs as a negative (loss-of-function) control; WT constructs were used as a positive control.
We selected variants that map throughout the length of the protein unlike some of the other functional studies that have focused mainly on the variants in the DNA-binding domain (Fig. 1b)33. Because the variants were not completely randomly selected, the number of variants with normal or abnormal function does not reflect the overall frequency of pathogenic or benign variants in BRCA2. All 88 variants are listed using HGVS nomenclature in Supplementary Table 1. For simplicity and readability, the variants are identified in the text by using the single letter amino acid code to describe the change.
To evaluate the functional consequences of BRCA2 VUS, we generated the selected variants in BAC containing full-length BRCA2. We confirmed the expression of the variants in mESC by reverse transcription polymerase chain reaction (RT-PCR). Two independent clones expressing each variant were subjected to CRE-mediated deletion of conditional Brca2 allele. The reason for examining two independent clones expressing each BRCA2 variant was to rule out any position effect associated with the site of integration of the BAC DNA into the ES cell genomic DNA. A functional HPRT1 minigene is generated upon deletion of the conditional Brca2 allele that allows selection of recombinant clones on hypoxanthine–aminopterin–thymidine (HAT) media (Fig. 1a). Loss of conditional Brca2 allele in HAT-resistant (HATr) colonies was further confirmed by Southern hybridization (Supplementary Fig. 1). Rescue rate was calculated based on the total number of viable Brca2KO/KO mES cells that survived in HAT media over the total number cells plated. In each batch of the assay, the number of surviving colonies for each variant was compared to the number of surviving colonies for WT BRCA2 (Supplementary Table 2).
Variants that failed to result in viable Brca2KO/KO ES cells or showed reduced survival compared to WT controls (V220Ifs, R2336L, R2336P, Q2561P, F2562L, G2585R, G2596R, G2596E, D2611G, H2623R, K2630Q, L2647P, R2659G, R2659K, R2659T, S2670L, L2686P, S2691F, L2721H, D2723A, D2723V, Y2726C, R2784W, A2786P, W2788S, G2793R, Q2829X, Q2829L, Q2829R, C3069X, D3073G, and C3233Wfs) were further examined to confirm the expression of BRCA2 by Western blot analysis (Supplementary Fig. 2a). Brca2KO/KO ES cells expressing truncating variants such as Q742X, E1308X, S1882X, S1926Rfs, R2488Rfs, L2740X, T2708Nfs, and Y3225Ifs variants were confirmed by RT-PCR due to failure to detect the truncated protein (Supplementary Fig. 2b). We failed to detect protein expression at levels comparable to WT in any ES cell clones with the variants R2336P, R2336L, S2691F, Q2829X, and C3069X (Supplementary Fig. 2a). It is possible that these variants result in an unstable protein. We have previously reported that c.7007 G > A (R2336H) results in exon skipping and the ES cells expressing the variant show lower protein levels compared to WT24. In cells expressing C3069X variant, we detected a very low level of expression of the protein in only one clone (Supplementary Fig. 2a). Inability to detect the C3069X protein in multiple RT-PCR positive clones suggests that the protein truncation may be affecting protein stability.
Functional analysis of variants: effect on sensitivity to DNA-damaging agents
BRCA2 plays a major role in maintaining the genomic integrity by repairing DNA double strand break (DSB) by homologous recombination (HR) as well in protecting stalled replication forks36,37,38,39. BRCA2 is also required for repairing DNA interstrand cross-links40. Because of its involvement in multiple repair processes, cells lacking BRCA2 show hypersensitivity to a number of different DNA-damaging agents20. Therefore, variants that rescued the lethality of Brca2KO/KO ES cells, partially or fully, were further tested for BRCA2 function by examining the sensitivity of rescued cells to six different agents: poly (ADP-ribose) polymerase (PARP) inhibitor (olaparib), DNA topoisomerase inhibitor (camptothecin), DNA interstrand cross-linking agent (cisplatin and mitomycin C, (MMC)), alkylating agent (methyl methane-sulfonate, MMS) and DSB inducer (ionizing radiation (IR)). Sensitivity of Brca2KO/KO ES cells for each variant was compared with Brca2KO/KO mESC expressing WT BRCA2 (Supplementary Fig. 3 and Table 3).
VarCall model for prediction of functional status
We developed a VarCall classification model for the data obtained from the cell viability (survival on HAT) assay as well as for the drug sensitivity (DS) assay to estimate the PIF of the VUS. The HAT survival and DS assay data were modeled both separately and together. The joint model assumed that the two forms of data are conditionally independent given variant pathogenicity status. This assumption implies that the two assays are correlated with binary function status, but given that a variant is functional or nonfunctional, the readouts from the two assays vary independently around their functional status-specific means. This does not, however, restrict the effects to be consistent with one another: population variation in an assay readout within the functional and nonfunctional groups may overlap. We evaluated each of the three resulting models (HAT, DS, and HAT + DS) on basis of the accuracy with which it predicted the status of the ten previously classified variants using a leave-one-variant-out analysis described below. The combined approach proved to be more powerful: jointly modeling the two data types allowed clear separation of VUS as neutral or pathogenic.
VarCall model of cell viability
Eighty-eight variants were evaluated using the cell viability (HAT) assay, each batched in duplicate with a WT BRCA2 construct (positive control). The number of surviving mES cells was recorded along with the total number of cells that were plated. Survival fractions were computed from these data and the average survival of two independent clones were determined (Supplementary Table 2 and Fig. 2a). Because only two clones expressing each variant were used to address any concerns related to the impact of the BAC integration site, standard deviation values were not obtained. However, it is evident that although the actual survival percentages differ between the two clones, no major differences (“full rescue” vs. “no rescue”) were observed for any variant (Supplementary Table 2). The HAT survival data were modeled as having a zero-inflated negative binomial distribution with a mean that depends on a random effect for batch and a random effect for variant. The latter follows the two-component normal mixture model common to all VarCall models. All VarCall models are classification tools because the true pathogenicity status of only a subset of the variants in any given analysis is known and these are labeled as functional or nonfunctional controls, as appropriate. The remaining variants have their impact on function status treated as an unknown binary variable, IF, indicating their status (impacted function/nonfunctional = 1; no impact/functional = 0). Statistical inference therefore focuses on estimating the posterior probability that IF = 1 for each such variant given the data. We refer to this as the variant’s PIF.

a Cell survival fractions are plotted for each variant ordered by average survival fraction. Known neutral variants are highlighted in green and known pathogenic variants are highlighted in red. The box plotted for each variant range from the lower replicate value up to the upper replicate value with the mean value highlighted at the midpoint; for the WT we have plotted a box and whisker plot of the distribution of WT values across batches (the box ranges from the first-to-third quartile with a horizontal line plotted at the median, whiskers extend from the box down to the smallest value and from the box up to the largest value within ±1.5 standard deviations of the median and points beyond this limit are depicted individually). b A plot of the estimated PIFs from the cell survival data VarCall model, depicted in increasing order. Posterior mean estimates are plotted as dots; whiskers extend from the lower to upper limits of 95% posterior credible intervals.
We estimated the accuracy of the VarCall models based on their predictions of the ten previously classified variants (P168T, F1524V, G1529R, D2312V, K2411T and Q742X, E1308X, L2740X, C3069X, D3073G). All analyses also included V220Ifs and the WT as negative (non-function) and positive (functional) controls, respectively. We labeled the two controls and ten previously classified variants as functional/not functional when classifying the VUS. In order to characterize the accuracy of the approach, we ran ten additional analyses, where in each we systematically left one of the ten (six missense and four nonsense variants) previously classified variants unlabeled and estimated its classification status with the remaining nine known +2 controls (WT and V220Ifs) labeled. We report and plot classification probabilities for the VUS based on the full analysis and for the known missense and nonsense variants based on the leave-one-variant-out analyses. We base our estimates of classification accuracy on the latter set of values.
We classified variants as “functional”, “nonfunctional”, or “indeterminate” based on the probability of impact on function (PIF) estimated by the VarCall model. In particular, we define variants as functional that have PIF ≤ 0.05, 0.05 < PIF ≤ 0.99 as indeterminate and those with PIF > 0.99 as nonfunctional. Figure 2b plots the estimated PIFs and associated 95% interval estimates in increasing order. Note that our cell survival (HAT assay) VarCall model co-clusters WT and 39 variants including S2483G and those to its left as likely functional and 39 variants to the right of R2336P as likely nonfunctional. The model classified all five benign variants correctly and four of five pathogenic variants correctly, leaving one (D3073G) unclassified with a PIF = 0.889. While our resolution is limited by the modest number of unlabeled variants of known status, we estimate sensitivity of the HAT-based classification procedure to be 0.69 (95% high density interval (HDI) from 0.37 to 0.98) and its specificity to be 0.85 (0.58, 1.00). The scaled Brier score was estimated to be 0.0051.
VarCall model of sensitivity to DNA damaging agents
Fifty-six variants that supported viability of Brca2KO/KO ES cells, partially or similar to WT BRCA2, were evaluated using the DS assay. Each variant was evaluated using two independent clones, batched with the WT expressing ESC control and was subjected to various concentrations/doses of each of the six DNA damaging agents. In all, the DS data comprises of 5488 measurements of the survival fraction and each measurement represents the average of three values.
The DS assay data are assumed to follow a multilevel dose response model. We evaluated the family of dose response models described by Slob (2002) over the range of variants and drug assays and found that curves of the form y = exp(−(x/b)d), where x is dose, y is survival fraction and b and d are parameters, provide a robust and accurate fit (Fig. 3a)41. After complementary log–log transformation of this parameterization, the response is linear in the log of dose. We model the dose response data on this scale, separately normalizing the log dose variable for each drug.

a A plot of the observed MMS assay survival fractions for variant F1524V (blue points); paired wildtype values are plotted as green points and the distributions of WT values across batches are depicted as boxplots (open circles represent outlier values). Note the characteristic nonlinear decline in survival fraction from 1.0 (100%) to zero as a function of concentration. This relationship is modeled well using the chosen family of dose response curves. b Bi-clustered heatmaps of the drug sensitivity model intercept parameters from the drug sensitivity model. Cells in the plot represent variant- (column) and drug-specific (row) effects. Higher survival percentage values are plotted in shades of yellow; lower values in shades of red and orange. The lower the value of eta, the faster the survival fractions decline as a function of dose, i.e., the greater the sensitivity of the variant. Variants tend to co-cluster as likely pathogenic or likely neutral based on these estimates (the green and red bars at the top of the plot indicate the known benign and known pathogenic variants, respectively). c Slope vs. intercept scatter plot of the estimated variant-level drug sensitivity effects for each variant. Contours of the bivariate VarCall mixture model components are plotted in green (neutral component) and red (pathogenic). Variants plotted at similar contour levels for both components will have equivocal PIF estimates; variants plotted at dissimilar levels (e.g., those in the upper left corner) will be more clearly classified (see panel d). d Estimated PIFs plot from the drug sensitivity data VarCall model, depicted in increasing order. Dots represent posterior mean estimates with the whiskers extend from the lower to upper limits of 95% posterior credible intervals.
The model includes random effects that adjust the response variable for location and scale shifts due to batch and due to the drugs; the resulting variable is modeled as a simple linear regression on the log of dose with drug- and variant-specific intercept and slope coefficients. To ensure parameter identifiability, location and scale shifts for one drug and one batch are set to 0 (for location) and 1 (for scale). The bi-clustering of the DS model’s drug- and variant-specific intercept terms provides a side-by-side comparison of the drug sensitivities of individual variants in which each variant is depicted in a single column and in which its sensitivities to the individual drugs/treatments are pictured in the various rows (Fig. 3b). It reveals distinct drug response signatures among the known benign (highlighted in green) and among the known pathogenic variants (red) (Fig. 3b). These are segregated into the two main clusters defined by the top branching in the dendrogram; the effects profiles of the two groups are distinct with lower values corresponding to greater sensitivities (depicted in red and dark orange) typical of the left, loss-of-function cluster and lesser sensitivities (light oranges and yellows) typical of the functionally unimpaired cluster on the right.
The individual drug effects are variable (SD(intercept) = 0.86; SD(slope) = 0.55) relative to the differences (1.24 and 0.62, respectively) between their average effects in the functional and nonfunctional components of the mixture model. However, they provide complementary information: pairwise correlations between the drug treatment effects across variants range from near zero to 0.76 with a median of 0.49. This is evident in Fig. 3b where, for example, we see that the IR effect is often high (depicted in yellow) in variants where the PARPi effect is modest or low (oranges to reds) and vice versa. It is, therefore, useful to borrow strength from multiple agents. Indeed, combining the six results in a much less variable pair of composite drug effects: the intercept effect has SDs of 0.38 (functional component in the mixture model) and 0.34 (nonfunctional), while the slope effect has SDs of 0.17 and 0.11, respectively. Despite this sharpening of the drug signal, the two components of the mixture model retain a large amount of overlap (Fig. 3c), resulting in numerous equivocal calls when used alone for classification (Fig. 3d).
The variant- and drug-specific intercept and slope coefficients are random effects centered at variant-specific values. We perform variant classification based on the quantities measuring the overall drug sensitivities of the variants. In particular, we assume that variant-level slope and intercept terms follow a bivariate normal mixture model, with one component reflecting variation in the drug effects among neutral variants (green contours) and the other reflecting variation among pathogenic variants (red contours) (Fig. 3c). As with all VarCall models, we classify each variant according to the posterior probability of the variant belonging to the pathogenic component of the model.
Three of the known pathogenic variants and 29 of the VUS failed to rescue function and were not evaluated using the DS assay. Of the remaining 56 variants, 38 had PIFs in the indeterminant range, including four known neutral variants; 2 VUS and 3 pathogenic controls were called nonfunctional and 13 (including one neutral control) were classified as functional (Fig. 3d). PIFs from the DS model reflect greater classification uncertainty than those from the cell survival model (Fig. 2b). PIFs ranged from 0.044 up to 0.28 among the 5 known benign variants; the three known pathogenic variants had PIFs of 1 (V220Ifs), 0.9924 (C3069X), and 0.9996 (D3073G). The scaled Brier score, estimated using the seven labeled variants, was 0.1027.
Combined model of cell survival and DS assay
We created a combined model for the cell survival and DS data that assumes their conditional independence given pathogenicity status. In particular, variants with both HAT and DS data provide information for the model’s HAT and DS parameters and both data types simultaneously and independently contribute to the estimation of the pathogenicity status indicator of those variants; variants with only HAT data contribute information to the model’s HAT parameters only and these data contribute solely to estimation of their classification indicators. Adding the DS data to the HAT model provides increased resolution for estimating the parameters of the HAT data model by providing complementary information on the pathogenicity status of the variants with DS data.
The pathogenic and neutral components of the variant-specific drug effects from the combined model (Fig. 4a) are better separated than those of the model for the DS assay data alone (Fig. 3c) and the variants of known status all co-cluster under the appropriate distributional component. Indeed, addition of the HAT survival data to the DS data leads to substantial refinement of the PIFs and results in more certain classifications and greater accuracy (Fig. 4b, Table 1): PIFs are closer to zero or one and the PIFs associated with the known neutral variants (green) are systematically closer to zero (all fall below the diagonal) and those associated with the known pathogenic variants (red) are systematically closer to one (all fall above the diagonal). Addition of the DS data to the cell survival data results in more modest changes to the estimated PIFs, however, it provides important resolution to variants that show evidence of rescued function. The effect on the PIFs inferred for these variants can be seen in Fig. 4c. With addition of the drug data, the PIF associated with the known pathogenic variant D3073G changed from 0.9996 to 0.9966 (Table 1). Several of the VUS show increased evidence of pathogenicity, most notably D2489G and R2336L, while others show decreased evidence (Fig. 4c).

a Slope vs. intercept scatter plot for the combined model. b Plot of the PIF from the HAT model (x-axis) against the PIF from the combined model (y-axis). c Plot of the PIF from the drug assay model (x-axis) against the PIF from the combined model (y-axis). d Plot showing the estimated PIFs plot from the combined VarCall model of HAT survival and drug sensitivity data, depicted in increasing order. Posterior mean estimates and represented as dots and the whiskers extend from the lower to upper limits of 95% posterior credible intervals.
The estimated PIFs and associated 95% interval estimates derived from the combined model are plotted in Fig. 4d. PIFs from the combined model reflect improved classification accuracy over those from the cell survival (Fig. 2b) and DS (Fig. 3d) models. Forty-one variants including F266L and those that are plotted to its left are classified as likely functional (PIF ≤ 0.05) (Fig. 4d and Table 1). The variant R2336P and the 40 variants that were plotted to its right are classified as likely nonfunctional (PIF > 0.99), whereas the remaining six variants (T1624A, V2728I, P3063S, I1884T, R2336L, and W2788S) are indeterminate (0.05 < PIF ≤ 0.99) (Fig. 4d and Table 1). The combined model demonstrates improved accuracy, correctly classifying all ten variants of known pathogenicity status: the largest PIF among the known benign variants was 0.0002, while the smallest PIF among the known pathogenic variants was 0.9966. We estimate both the sensitivity and specificity of classifications based on the combined model to be 0.846 (95% HDI from 0.58 to 1.00). The scaled Brier score was estimated to be 8 × 10−8.
Performance of VarCall model for mES cell-based functional assay
Finally, we tested the performance of our VarCall model by examining 25 BRCA2 variants that were previously analyzed by our mES cell-based approach22,23,24. Among these 25 variants, 5 are listed as benign and nine as pathogenic or likely pathogenic in ClinVar. The variants map to different regions of the protein and include 19 missense variants, 1 truncating variant, 1 splice site variant, and 4 in-frame deletion variants (Table 2). Those variants have been comprehensively characterized not just by their impact on cell viability and sensitivity to DNA damaging agents but also by IR-induced RAD51 foci formation, HR efficiency, cell proliferation, as well as impact on genomic instability by cytogenetic analysis. Our functional studies had revealed that 10 were likely to be neutral, 13 were likely to be pathogenic, and 2 variants exhibited an intermediate phenotype23,24. We had reported G25R to have no impact on cell viability but cells expressing this variant were mildly sensitive to DNA damaging agents and exhibited mild genomic instability compared to the other pathogenic variants23. In contrast, the variant lacking the 105 amino acids encoded by exons 4–7 (del exon 4–7) resulted in a mild reduction in cell viability but there was no effect of DNA damaging agents, cell proliferation, IR-induced RAD51 foci formation24.
We reanalyzed these variants using our VarCall models as an additional independent validation of the model. PIFs estimated by these models (HAT, DS, and HAT + DS) are plotted (Fig. 5). All variants of known status were called correctly by both the HAT and HAT + DS models (Fig. 5a, c). Specificity of both models was estimated to be 0.846 (95% HDI from 0.58 to 1.00), while sensitivity was estimated to be 0.867 (95% HDI from 0.63 to 1.00). Here, addition of the DS to the HAT data did not change the classification. However, comparing variants classified by both the DS and HAT models only one variant, del exon 4–7, was discordant: it was classified as nonfunctional (PIF = 1.00) by the HAT model and as functional by the DS model (PIF = 0.004).

Boxplots of the PIFs estimated for the validation set variants, plotted in increasing order. a Based on HAT model, b based on the DS model, and c based on the HAT + DS model. Note that variant del exon 4–7 is estimated to be neutral based on the HAT data and pathogenic based on the drug sensitivity assay. It remains unclassified when the data are combined.
Alternative splicing in pathogenic variants
We next characterized some of the BRCA2 variants that are predicted to be functionally null but our functional studies revealed that they are partially functional. The variants V220Ifs (c.658_659delGT [886delGT]) and C3233Wfs (c.9699_9702delTATG [9927del4]) are predicted to generate a premature stop codon in exon 8 and exon 27, respectively but we were able to detect protein, albeit at a reduced level as compared to WT (Supplementary Fig. 2a). Both variants were also able to rescue the lethality of Brca2KO/KO ES cells, albeit at low levels (Fig. 2). RT-PCR analysis using primers from exon 2 and exon 10 detected transcripts that lacked exon 7, 3′ 39 bp of exon 6 and exon 7, exon 3 and exons 3–7, in mES cells expressing V220Ifs (Supplementary Fig. 4). Transcripts lacking exon 7 in V220Ifs code for BRCA2 protein (exon 7 skipping deletes 115 bp and 2 bp deletion from exon 8 in V220Ifs brings the protein in-frame) with an internal deletion of 39 amino acids that have been shown to be dispensable for BRCA2 function (Supplementary Fig. 5)24. The transcript that lacks 3′ 39 bp of exon 6 and exon 7 will also code for a BRCA2 protein with an internal deletion of 52 amino acids in V220Ifs expressing variant (3′ 39 bp of exon 6 and exon 7 skipping deletes 154 and 2 bp deletion from exon 8 in V220Ifs brings the protein in-frame). This explains the detection of protein and the rescue of Brca2KO/KO ES cells viability in the cells expressing V220Ifs variant. We failed to detect any alternatively spliced transcripts in the C3233Wfs variant (Supplementary Fig. 4). The detected protein in the cells expressing the C3233Wfs variant is thus the truncated protein (Supplementary Fig. 2a). Based on clinical data, the C3233Wfs variant is considered benign and classified as a variant with “special interpretation”. This variant was found in trans with a known pathogenic variant in several individuals without developing FA and also does not segregate consistently with developing cancer in families harboring this variant42. The variant C3233Wfs results in a truncated BRCA2 protein that lacks nuclear localization signals and part of the RAD51 binding domain43,44 and it is also upstream of a known pathogenic variant that results in truncation at codon 3308 (Y3308X) (https://www.ncbi.nlm.nih.gov/clinvar/)20. In our assay Brca2KO/KO ES cells expressing C3233Wfs variant is also defective in both IR-induced RAD51 foci formation and also in protecting replication fork stability, the two known functions of BRCA2 (Supplementary Fig. 6). At present, it is unclear how this potentially pathogenic variant in our functional assay behaves as a benign variant based on familial segregation data.
We failed to detect any protein expression or changes in splicing pattern of T2708Nfs (c.8122dupA [8122insA]), though there were very few Brca2KO/KO ES cells in this variant after HAT selection. The rescued Brca2KO/KO ES cells showed the presence of mutant variant when we sequenced the region of the BAC from mES cells (data not shown). It is possible that few cells expressed very low levels of the protein due to alternative splicing that we failed to detect in RT-PCR or Western blot analysis.
Effect of BRCA2 variants on splicing
The variants G2281V, D2312V, D2312E, R2336L, R2336P, R2659G, R2659K, R2659T, Q2829X, Q2829G, and Q2829R are present at or nearby the consensus splice site of exons (Supplementary Table 1). All the variants except R2336L and R2336P either complemented the lethality of Brca2KO/KO ES cells or expressed the protein comparable to WT (Fig. 2 and Supplementary Fig. 2a). R2336L and R2336P are located at the splice donor site of exon 13 and they caused skipping of exon 13 and also of exons 12 and 13, which resulted in the generation of a premature stop codon in exon 14 (Supplementary Figs. 4 and 5). The variant G2281V is located at the splice donor site and the variants D2312V, D2312E are located near the splice acceptor site of exon 12. The G2281V and D2312V variants resulted in either complete or partial skipping of exon 12 whereas the D2312E variant did not affect splicing of exon 12 (Supplementary Figs. 4 and 5). None of these three variants had any effect on the rescue efficiency of Brca2KO/KO ES cells (Fig. 2). This is in agreement with our previous findings showing that exon 12 is dispensable for known BRCA2 functions22. The variants R2659G, R2659K, and R2659T are located at or near the splice acceptor site of exon 17 (Supplementary Table 1). The variants R2659K, R2659T results in exon 17 skipping that generates a protein with an internal deletion of 57 amino acids, whereas R2659G variant results in only a minor skipping of exon 17 (Supplementary Figs. 4 and 5). Skipping of exon 19 was observed in the cells expressing Q2829X, Q2829L and Q2829R variants, that results in internal deletion of 52 amino acids (Supplementary Figs. 4 and 5). The S2691F variant fails to complement the loss of Brca2 and the expression of protein was significantly reduced compared to WT (Fig. 2 and Supplementary Fig. 2a). In a minigene-based splicing assay, S2691F was reported to cause minor skipping (5.1%) of exon 1845. We further checked if this variant causes any aberrant splicing but we failed to detect any effect on splicing in the mES cells (Supplementary Fig. 4).
Discussion
Accurate determination of the pathogenicity of variants of uncertain clinical significance (VUS) is a major hurdle in the clinical interpretation of genetic testing results. Despite the progress made by individual laboratories and international collaborations and consortiums such as the ENIGMA and BRCA Exchange to classify variants using familial and clinical data, the vast majority of BRCA variants are VUS. This remains the biggest challenge for physicians and genetic counselors who have to offer guidance to individuals who are positive for a BRCA VUS. A number of functional assays including mES cell-based assays have been developed and are being used to classify BRCA2 variants to overcome this problem20,34. However, most functional assays determine the functional impact of variants without determining the probability of impact on function (PIF). An important consideration is how to best incorporate functional assay data into multifactorial predictive models. A computational tool called VarCall was previously used to evaluate 139 BRCA2 variants located at the C-terminal BRCA2 DNA-binding domain (DBD)33 using data from a BRCA2 HR-based functional assay. In this study, we have analyzed BRCA2 VUS using a mES cell-based functional assay and used our VarCall models to determine their probability of impact on function (PIF).
We developed novel VarCall models to classify VUS based on data obtained from a cell survival assay, sensitivity of the mES cells expressing BRCA2 variants to six DNA damaging drugs and to the combined effect of both assays. The VarCall models previously described were each structured for a single functional assay, one for a BRCA1 transcriptional activation assay and the other for a BRCA2 HR assay23,24. These models assumed a log-normal sampling model and included batch and variant random effects. The VarCall model developed for the present study was tailored to the multivariate assay data it generated. In particular, it utilizes a negative binomial sampling model for the HAT colony counts (cell survival) and a family of dose response models for the DS data, the latter representing a total of 40 survival measurements collected from 6 different agents at multiple concentrations or doses for each variant. Data from the two assays are independently batch corrected and the model includes a variant-specific random effect measuring function based on the HAT data and two variant-specific random effects measuring function based on the DS data. The two DS effects are modeled as correlated and independently combined with the HAT effect, conditional on binary pathogenicity status. This defines a multivariate, two-component mixture model that is used to estimate PIFs and variant classifications.
Based on the hypothesis that sensitivities to various DNA damaging agents reflect the same basic defect in BRCA2-mediated DNA repair, we treated a weighted average of the drug-specific effects as a common drug response effect, instead of treating them as six independent functional assays. While the combined effect of cell survival and drug assays are used to determine the PIF of any variant, variants that fail to rescue viability of Brca2KO/KO ES cells rely exclusively on the results of the cell survival data. In the combined HAT + DS model, only the HAT data directly inform PIFs for variants that fail to rescue, while the PIFs of those variants that do survive are directly informed by the DS data as well. This leads to more accurate estimates of the parameters associated with the two-component mixture model on basis of which these PIFs are estimated.
Among the 88 VUS analyzed in this assay, 41 showed >99% probability in favor of abnormal function and 41 showed >95% probability in favor of normal function. The variants, T1624A, V2728I, P3063S, I1884T, R2336L, and W2788S showed intermediate phenotype in our model (Fig. 6a and Table 1). Among these, five variants T1624A, V2728I, P3063S, I1884T, and R2336L, are close to having normal function (likely neutral) with PIFs in between 0.05 and 0.36, whereas W2788S is close to abnormal function with PIF 0.94 (>0.85 PIF < 0.99). Future studies will be focused on integrating the PIF values obtained from our functional assays into the posterior probability models that will help in assessment of the clinical relevance of a VUS46.

a Variants analyzed using VarCall method are compared to ClinVar, Align GVGD, BRCA Exchange, classification by multifactorial likelihood ratio and published BRCA2 functional assays. Colored boxes represent different classifications listed below. The MANO-B (mixed-allnominated-in-one (MANO)-BRCA) method of classification includes the classification by Ikegami et al. (2020), the ES assay includes the classification of variants using mouse ES cell-based assay reported by Mesman et al. (2019) and the HDR assay includes the classification of variants using HR assay reported by Guidugli et al. (2018)18,19,33. The Multifactorial classifications are based on the study by Parson et al.51. b Schematic representation of classified variants in different domains of BRCA2. Neutral, hypomorphic and pathogenic variants are marked in blue, yellow, and magenta colors, respectively. Different domains are marked below with the range of amino acids (aa) containing in each domain.
Classification of VUS based on posterior probabilities from a Bayesian “system”, which by construction, requires specification of prior probabilities has been suggested by Plon et al.29 previously. Some recent BRCA VUS classification models have used the Align GVGD sequence conservation model to specify these prior probabilities33,47,48. In contrast, in the VarCall models we describe here, we specified a non-informative prior distribution on each variant’s function status. This allows us to compare the calibration of our PIF estimates to the Align GVGD based prior probabilities. We found twenty out of 29 variants (~68%) that are Align-GVGD categories associated with moderate (Class C35–C55) to high (Class C65) prior probabilities are classified as nonfunctional or close to non-functional (W2788S with PIF 0.94) using our VarCall model (Fig. 6a). Interestingly, among the remaining nine variants that are Align-GVGD categories C35-C65 associated with moderate to high prior probabilities of pathogenicity but did not have impact on function based on our VarCall model, seven are located outside the DBD (Fig. 6b). Three (G2281V, D2312V, and D2312E) out of these seven variants are located at or close to the exon–intron junction (Supplementary Table 1). Two (G2281V and D2312V) result in full or partial exon 12 skipping but exon 12 is dispensable for BRCA2 function (Supplementary Figs. 4 and 5)22. Considering the high sensitivity and specificity of our assay, these results suggest that the Align-GVGD may over-predict the probability of pathogenicity for BRCA2 VUS. The VarCall model for the BRCA2 HDR assay also had significant discrepancies with the Align-GVGD prediction33. Variants with lower prior probabilities of pathogenicity (Class C0–C25) by Align-GVGD showed better agreement (~80%; 34 neutral or likely neutral out of 42 that are in class C0-C25) with our functional classification. Eight variants with lower prior probabilities of pathogenicity (Class C0–C25) by Align-GVGD that are classified as non-functional using our VarCall model, are located in the DBD. Recent calculations of prior probabilities of pathogenicity also take into account the location of the amino acid in the protein as well as the impact of the nucleotide on splicing (http://hci-priors.hci.utah.edu/PRIORS/)49. These prior probabilities of pathogenicity (PPP) show better agreement with the PIF values obtained by our VarCall model (Table 1 and Supplementary Table 1).
Interestingly, in our model, all pathogenic missense variants except two that affect splicing (R2336L and R2336P) are clustered in the DBD (Fig. 6b). It is not surprising because the function of BRCA2 in HR and replication is facilitated by the DBD located at the carboxy (C) terminus of the protein36,37,38,50. Our VarCall classifications shows high concordance with that of the HDR assay (22/24), mES cells based HDR assay performed by other groups (5/5) or with a recently published high-throughput functional assay based on complementation of PARPi sensitivity (15/17) (Fig. 6a)18,19,33. The variants V2728I and W2788S are classified as neutral or deleterious by HR assay whereas in our assay they have PIFs 0.10 and 0.94, respectively (Table 1)33. We have classified them as indeterminate but clearly V2728I is close to functional and W2728S is close to non-functional. The variant R2336P is classified as neutral by Ikegami et al.18, whereas this variant that affects splicing is pathogenic in our model and in agreement with ClinVar. This further raises a concern about classifying variants using cDNA based functional assays that fail to consider the potential effect of the variants on splicing. Importantly, there are no discordances with the variants that scored pathogenic or neutral based on our VarCall model and the pathogenic/likely pathogenic and benign/likely benign classification in ClinVar except V2728I and R2336L, another variant that affects splicing. V2728I is classified as benign, and in our model it is indeterminate variant with PIF of 0.10 that is closer to neutrality (>85% probability) (Table 1). In ClinVar, R2336L is listed as “likely pathogenic” whereas based on our VarCall classification it appears to be indeterminate variant with PIF of 0.36.
We also compared the results of our VarCall model with the recent classification of BRCA1/2 variants using multifactorial likelihood ratios and found 13 out of 19 variants to be classified similarly51 (Fig. 6a). Among the six variants that were not in concordance, V2728I is considered benign according to the multifactorial model, but classified as indeterminate by our assay with PIF of 0.10 (in favor of normal function with >85% probability) (Table1). The remaining five variants (S869L, R2488K, D2489G, V2739I, and Q2829R) were classified as uncertain by the multifactorial model. Three of these variants (S869L, R2488K, and V2739I) showed probability in favor of normal function and two (D2489G and Q2829R) showed probability in favor of abnormal function in our assay system (Fig. 6a). Additional clinical and/or functional data are needed to ascertain the impact of these variants.
In conclusion, we have performed an extensive functional analysis of BRCA2 variants and demonstrated that our mES-cell-based functional assay is a robust tool for classification of BRCA2 VUS. Furthermore, our VarCall classification model can be used to determine the probability of impact on function that can aid in the clinical annotation of VUS. However, the disease risk associated with any VUS must be cautiously interpreted based on any in vitro functional assay either alone or in combination with in silico prediction tools. As is true of other BRCA2 functional assays, our results are not intended to be directly used for clinical risk assessment. Given that both sensitivity and specificity of our assay are based on relatively small number of established pathogenic and benign variants, additional studies are warranted to further validate the reliability of our mESC-based assay and the VarCall models.
Methods
Variant nomenclature and in silico analysis
HGVS nucleotide nomenclature reflects cDNA numbers with +1 corresponding to the A of the ATG initiation codon in the reference sequence of BRCA2 (GenBank accession number NM_000059.3). Variants were examined for evolutionary conservation using Align-GVGD (http://agvgd.hci.utah.edu/agvgd_input.php). Grantham variation (GV) and Grantham deviation (GD) scores combine protein multiple sequence alignments and the physiochemical properties of the amino acids. The GV and GD scores are C0, C15, C25, C35, C45, C55, C65, with C0 being most likely neutral and C65 being most likely pathogenic.
Generation of BRCA2 variant expressing PL2F7 mES cells
A BAC clone (CTD-2342K5 with a 127 kb insert) containing full-length BRCA2 in SW102 cells was used to generate variants by a recombineering method as described previously23,52. All BACs were sequenced to determine that no undesired mutations were generated after recombineering. Oligonucleotide sequences are available upon request. After electroporating BAC DNA (20 µg) carrying various mutant alleles of BRCA2 into 1.0 × 107 PL2F7 mES cells, cells were selected in the presence of G418 (Invitrogen) and characterized as described previously20. RT-PCR was carried out using the Titan One Tube RT-PCR system (Roche) following the manufacturer’s protocol to confirm BRCA2 expression. Primers used are from exon 11 (5′-TGGTTTTGTCAAATTCAAGAATTGG-3′) and exon 14 (5′-CCAATCAAGCAGTAGCTGTAACTTTCAC-3′). Amplified 627 bp product was detected in agarose gel. After the BAC containing mESC were obtained, presence of the correct variant and lack of undesired mutations were confirmed by sequencing again.
BRCA2 functional analysis
For mES cell viability assay, the conditional allele of Brca2 in mES cells expressing each variant was deleted by electroporating 20 μg of Pgk-Cre plasmid as described previously23. For each variant two independent BRCA2 expressing clones were used to address any variability due to the site of integration of the BAC clone in the ES cells. After electroporation, 1 × 106 cells were plated in two 100 mm dishes and one was used for selection in the HAT media (Gibco) to select recombinant colonies. The second 100 mm dish was used as plating efficiency control. The mES cell colonies were visualized by staining with methylene blue (2% methylene blue (wt/vol) in 70% ethanol for 15 min followed by washing in 70% ethanol). Sensitivity assays to different drugs and IR were performed by XTT assay as described previously20. In brief, 10,000 ES-cells per well (15,000 cells per well for slow-growing mutants to compensate for lower seeding and growth efficiency) were seeded in 96-well plates. After 18–20 h, cells were treated with different damaging agents in triplicate. Concentrations/dose used were: Camptothecin: 0, 2.5, 5, 25, 50, 100, and 200 µM; Mitomycin C(MMC): 0, 5, 10, 20, 40, 60 ng/ml; Cisplatin: 0, 0.2, 0.4, 0.6, 1.0, 1.2, 1.5 µM; methyl methanesulfonate (MMS): 0, 50, 10, 15, 20, 30, 40 µg/ml; PARP inhibitor (olaparib): 0.01, 0.1, 1, 10 µM; IR: 0, 0.5, 1, 2, 4, and 6 Gy. Plates were exposed to a 137Cs source at 146.3 rad/min without media change for γ-irradiation. After irradiation, fresh media was added. Cell viability of treated cells was determined relative to untreated after 72 h. using XTT assay. All values were adjusted for a no-cells control.
To count the colonies, petri dishes were stained with 0.3% methylene blue and scanned at a resolution of 600 dpi, and processed with ImageJ software (NIH, Bethesda, MD). Area of image near dish walls was not analyzed. Because colonies have different size and morphology, and may overlap, the ImageJ script (see “Supplementary methods”) relied on user input to select parameters which result in optimal identification of individual colonies, as judged by visualization with overlaid labels. The parameters were kept uniform across all dataset.
BRCA2 expression analysis by Western blot
Proteins (15–20 µg) extracted in radioimmunoprecipitation assay buffer (50 mm Tris–HCl, pH 7.4, 1 mm ethylenediaminetetraacetic acid, 150 mm NaCl, 0.1% sodium dodecyl sulphate, 1% Triton X-100, 0.25% sodium deoxycholate, 1 mm sodium fluoride, 1 mm orthovanadate) were separated using Bio-Rad 3–8% tris-acetate gradient gel (Bio-Rad) electrophoresis for Western blot analysis. Rabbit polyclonal BRCA2 (recognizes an epitope between residues 450-500) antibody (BETHYL lab, Cat # A303-434A-T-1, 1:2000 dilution), rabbit monoclonal GAPDH antibody (Cell Signaling technologies, Cat# 5174, 1:200,000 dilution) and mouse monoclonal Vinculin antibody (Santa Cruz biotech, Cat# sc25336, 1:200,000 dilution) were used to detect proteins. ECL plus Western blotting detection system (Amersham) was used for chemiluminescent detection. All Western blots were derived from the same experiment and were processed in parallel.
Splicing analysis in mES cells expressing BRCA2 variants
To detect the effect of potential splice site variants on aberrant splicing, total RNA was extracted using RNA-BEE (Tel-Test, Inc.) according to the manufacturer’s protocol. RT-PCR analysis was performed using the Qiagen one-step RT-PCR Kit (Qiagen) to detect an alternatively spliced form of BRCA2, following the manufacturer’s protocol. RT-PCR fragments were run on a 2% agarose gel. DNA fragments were eluted from the gels and directly sequenced using the primers used for RT-PCR. Sequence of PCR primers are provided in Supplementary Table 4.
RAD51 foci formation assay
Cells were irradiated with 10 Gy radiation and fixed in 4% paraformaldehyde 5 h post IR in PBS followed by permeabilization with 0.1% TritonX-100 in PBS. Antibody staining and imaging was done as described previously20. Rabbit polyclonal RAD51 antibody (Calbiochem, Cat# PC-130, 1:100 dilution) and mouse monoclonal anti phospho-histone H2A.X (Millipore, Cat# 05-636, 1:1000 dilution) were used for staining.
DNA fiber assay
The DNA fiber assay was carried out as described previously53. Briefly, cells were pulsed sequentially by 8 μg ml−1 CldU for 15 min followed by 90 μg ml−1 IdU for 15 min, and then were treated with 4 mM HU for 3 h. Cells were harvested in phosphate-buffered saline (PBS). Approximately, 3 × 105 cells were lysed with lysis buffer (200 mM Tris-HCl (pH 7.4), 50 mM EDTA, 0.5% sodium dodecyl sulphate) on glass slides and incubated at room temperature for 8 min before DNA fiber was spread. Methanol and acetic acid (3:1) was used to fix the fibers followed by rehydration by PBS and denaturation in 2.5 M HCl for 1 h. Staining was done by incubating with anti-BrdU antibody (mouse, #347580, Becton Dickinson, 1:100 dilution) and anti-BrdU antibody (rat, ab6326, Abcam, 1:500 dilution) at 4 °C overnight. AlexaFluo488-conjugated anti-mouse IgG secondary antibody and AlexaFluo594-conjugated anti-rat IgG secondary antibody was used for visualization. The images were captured in Zeiss Axio Imager Z1 microscope and the fiber length was measured using ImageJ software (NIH).
Statistical computations
All higher-level computations were carried out in the R programming language54. We used JAGS55 to fit all models using Markov chain Monte Carlo (MCMC) algorithms. We ran each MCMC algorithm for 10,000 burn-in iterations followed by another 500,000 iterations. We ignored the burn-in iterations and retained every 100th of the remaining samples for inference. We estimated marginal posterior means, standard deviations and 95% HDIs of the model parameters by their sample-based counterparts. We carried out standard output analysis to assess for convergence and to verify that the chains were run long enough.
We estimated sensitivity and specificity of the classifications using a model-based analysis. In particular, we fit a Bayesian Dirichlet-multinomial model to the conditional distributions over the classification categories given true pathogenicity status, assuming Jeffreys’ prior distribution on the vector of multinomial probabilities for each conditional distribution. We estimated sensitivity and specificity by the associated posterior expected probabilities and report 95% Bayesian high density intervals for each parameter. In addition, we report the scaled Brier score, a summary of the discordance between the known binary classifications and the PIFs that result from a given model. Computations were carried out within a reproducible research framework using the R package knitr56.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
All raw data and the BACs or cell lines generated for this study are available upon request.
Code availability
The code and data are available upon request.
References
Bray, F. et al. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 68, 394–424 (2018).
Kuchenbaecker, K. B. et al. Risks of breast, ovarian, and contralateral breast cancer for BRCA1 and BRCA2 mutation carriers. J. Am. Med. Assoc. 317, 2402–2416 (2017).
Wooster, R. et al. Identification of the breast cancer susceptibility gene BRCA2. Nature 378, 789–792 (1995).
Wang, Y. et al. Rare variants of large effect in BRCA2 and CHEK2 affect risk of lung cancer. Nat. Genet. 46, 736–741 (2014).
van Asperen, C. J. et al. Cancer risks in BRCA2 families: estimates for sites other than breast and ovary. J. Med. Genet. 42, 711–719 (2005).
Murphy, K. M. et al. Evaluation of candidate genes MAP2K4, MADH4, ACVR1B, and BRCA2 in familial pancreatic cancer: deleterious BRCA2 mutations in 17%. Cancer Res. 62, 3789–3793 (2002).
Breast Cancer Linkage, C. Cancer risks in BRCA2 mutation carriers. J. Natl Cancer Inst. 91, 1310–1316 (1999).
Cline, M. S. et al. BRCA Challenge: BRCA exchange as a global resource for variants in BRCA1 and BRCA2. PLoS Genet. 14, e1007752 (2018).
Tavtigian, S. V., Samollow, P. B., de Silva, D. & Thomas, A. An analysis of unclassified missense substitutions in human BRCA1. Fam. Cancer 5, 77–88 (2006).
Schwarz, J. M., Cooper, D. N., Schuelke, M. & Seelow, D. MutationTaster2: mutation prediction for the deep-sequencing age. Nat. Methods 11, 361–362 (2014).
Mathe, E. et al. Computational approaches for predicting the biological effect of p53 missense mutations: a comparison of three sequence analysis based methods. Nucleic Acids Res. 34, 1317–1325 (2006).
Kumar, P., Henikoff, S. & Ng, P. C. Predicting the effects of coding non-synonymous variants on protein function using the SIFT algorithm. Nat. Protoc. 4, 1073–1081 (2009).
Adzhubei, I. A. et al. A method and server for predicting damaging missense mutations. Nat. Methods 7, 248–249 (2010).
Spurdle, A. B. et al. ENIGMA—evidence-based network for the interpretation of germline mutant alleles: an international initiative to evaluate risk and clinical significance associated with sequence variation in BRCA1 and BRCA2 genes. Hum. Mutat. 33, 2–7 (2012).
Guidugli, L. et al. Functional assays for analysis of variants of uncertain significance in BRCA2. Hum. Mutat. 35, 151–164 (2014).
Carvalho, M. A., Couch, F. J. & Monteiro, A. N. Functional assays for BRCA1 and BRCA2. Int J. Biochem. Cell Biol. 39, 298–310 (2007).
Findlay, G. M. et al. Accurate classification of BRCA1 variants with saturation genome editing. Nature 562, 217–222 (2018).
Ikegami, M. et al. High-throughput functional evaluation of BRCA2 variants of unknown significance. Nat. Commun. 11, 2573 (2020).
Mesman, R. L. S. et al. The functional impact of variants of uncertain significance in BRCA2. Genet. Med. 21, 293–302 (2019).
Kuznetsov, S. G., Liu, P. & Sharan, S. K. Mouse embryonic stem cell-based functional assay to evaluate mutations in BRCA2. Nat. Med. 14, 875–881 (2008).
Chang, S., Biswas, K., Martin, B. K., Stauffer, S. & Sharan, S. K. Expression of human BRCA1 variants in mouse ES cells allows functional analysis of BRCA1 mutations. J. Clin. Investig. 119, 3160–3171 (2009).
Li, L. et al. Functional redundancy of exon 12 of BRCA2 revealed by a comprehensive analysis of the c.6853A>G (p.I2285V) variant. Hum. Mutat. 30, 1543–1550 (2009).
Biswas, K. et al. Functional evaluation of BRCA2 variants mapping to the PALB2-binding and C-terminal DNA-binding domains using a mouse ES cell-based assay. Hum. Mol. Genet. 21, 3993–4006 (2012).
Biswas, K. et al. A comprehensive functional characterization of BRCA2 variants associated with Fanconi anemia using mouse ES cell-based assay. Blood 118, 2430–2442 (2011).
Bouwman, P. et al. A high-throughput functional complementation assay for classification of BRCA1 missense variants. Cancer Discov. 3, 1142–1155 (2013).
Mesman, R. L. S. et al. Alternative mRNA splicing can attenuate the pathogenicity of presumed loss-of-function variants in BRCA2. Genet. Med. 22, 1355–1365 (2020).
Sirisena, N. et al. Functional evaluation of five BRCA2 unclassified variants identified in a Sri Lankan cohort with inherited cancer syndromes using a mouse embryonic stem cell-based assay. Breast Cancer Res. 22, 43 (2020).
Stauffer, S., Biswas, K. & Sharan, S. K. Bypass of premature stop codons and generation of functional BRCA2 by exon skipping. J. Hum. Genet. 65, 805–809 (2020).
Plon, S. E. et al. Sequence variant classification and reporting: recommendations for improving the interpretation of cancer susceptibility genetic test results. Hum. Mutat. 29, 1282–1291 (2008).
Spurdle, A. B. et al. Towards controlled terminology for reporting germline cancer susceptibility variants: an ENIGMA report. J. Med. Genet. 56, 347–357 (2019).
Brnich, S. E. et al. Recommendations for application of the functional evidence PS3/BS3 criterion using the ACMG/AMP sequence variant interpretation framework. Genome Med. 12, 3 (2019).
Iversen, E. S. Jr., Couch, F. J., Goldgar, D. E., Tavtigian, S. V. & Monteiro, A. N. A computational method to classify variants of uncertain significance using functional assay data with application to BRCA1. Cancer Epidemiol. Biomark. Prev. 20, 1078–1088 (2011).
Guidugli, L. et al. Assessment of the clinical relevance of BRCA2 missense variants by functional and computational approaches. Am. J. Hum. Genet. 102, 233–248 (2018).
Guidugli, L. et al. A classification model for BRCA2 DNA binding domain missense variants based on homology-directed repair activity. Cancer Res. 73, 265–275 (2013).
Easton, D. F. et al. A systematic genetic assessment of 1,433 sequence variants of unknown clinical significance in the BRCA1 and BRCA2 breast cancer-predisposition genes. Am. J. Hum. Genet. 81, 873–883 (2007).
Xia, F. et al. Deficiency of human BRCA2 leads to impaired homologous recombination but maintains normal nonhomologous end joining. Proc. Natl Acad. Sci. USA 98, 8644–8649 (2001).
Schlacher, K. et al. Double-strand break repair-independent role for BRCA2 in blocking stalled replication fork degradation by MRE11. Cell 145, 529–542 (2011).
Moynahan, M. E., Pierce, A. J. & Jasin, M. BRCA2 is required for homology-directed repair of chromosomal breaks. Mol. Cell 7, 263–272 (2001).
Sharan, S. K. et al. Embryonic lethality and radiation hypersensitivity mediated by Rad51 in mice lacking Brca2. Nature 386, 804–810 (1997).
D’Andrea, A. D. & Grompe, M. The Fanconi anaemia/BRCA pathway. Nat. Rev. Cancer 3, 23–34 (2003).
Slob, W. Dose-response modeling of continuous endpoints. Toxicol. Sci. 66, 298–312 (2002).
Rosenthal, E., Moyes, K., Arnell, C., Evans, B. & Wenstrup, R. J. Incidence of BRCA1 and BRCA2 non-founder mutations in patients of Ashkenazi Jewish ancestry. Breast Cancer Res. Treat. 149, 223–227 (2015).
Roy, R., Chun, J. & Powell, S. N. BRCA1 and BRCA2: different roles in a common pathway of genome protection. Nat. Rev. Cancer 12, 68–78 (2011).
Gudmundsdottir, K. & Ashworth, A. The roles of BRCA1 and BRCA2 and associated proteins in the maintenance of genomic stability. Oncogene 25, 5864–5874 (2006).
Fraile-Bethencourt, E. et al. Functional classification of DNA variants by hybrid minigenes: Identification of 30 spliceogenic variants of BRCA2 exons 17 and 18. PLoS Genet. 13, e1006691 (2017).
Toland, A. E. & Andreassen, P. R. DNA repair-related functional assays for the classification of BRCA1 and BRCA2 variants: a critical review and needs assessment. J. Med. Genet. 54, 721–731 (2017).
Tavtigian, S. V., Greenblatt, M. S., Lesueur, F., Byrnes, G. B. & Group, I. U. G. V. W. In silico analysis of missense substitutions using sequence-alignment based methods. Hum. Mutat. 29, 1327–1336 (2008).
Li, H. et al. Classification of variants of uncertain significance in BRCA1 and BRCA2 using personal and family history of cancer from individuals in a large hereditary cancer multigene panel testing cohort. Genet. Med. 22, 701–708 (2020).
Vallee, M. P. et al. Adding in silico assessment of potential splice aberration to the integrated evaluation of BRCA gene unclassified variants. Hum. Mutat. 37, 627–639 (2016).
Yang, H. et al. BRCA2 function in DNA binding and recombination from a BRCA2-DSS1-ssDNA structure. Science 297, 1837–1848 (2002).
Parsons, M. T. et al. Large scale multifactorial likelihood quantitative analysis of BRCA1 and BRCA2 variants: An ENIGMA resource to support clinical variant classification. Hum. Mutat. 40, 1557–1578 (2019).
Biswas, K., Stauffer, S. & Sharan, S. K. Using recombineering to generate point mutations:galK-based positive-negative selection method. Methods Mol. Biol. 852, 121–131 (2012).
Biswas, K. et al. BRE/BRCC45 regulates CDC25A stability by recruiting USP7 in response to DNA damage. Nat. Commun. 9, 537 (2018).
R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. (Vienna, Austria, 2016).
Plummer, M. in Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC, 2003).
Xie, Y. Dynamic Documents With R and Knitr. Second edition. (CRC Press/Taylor & Francis, 2015).
Acknowledgement
We thank members of our laboratory for helpful discussions and suggestions. We thank Susan Lynn North for her technical help. We also thank Drs. Suhas Kharat, Arun Mishra Satheesh Sengodan, and Sounak Sahu for their comments and critical review of the paper. The research is supported by the Intramural Research Program, Center for Cancer Research, U.S. National Cancer Institute (SKS). The research reported here was also supported by NIH grants 2U01-CA116167-06A1 (ESI and GBL) and 5P50-CA116201-13 (ESI). This project has been funded in whole or in part with Federal funds from the National Cancer Institute, National Institutes of Health, under Contract No. 75N91019D00024 (V.M.). The content of this publication does not necessarily reflect the views or policies of the Department of Health and Human Services, nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government.
Author information
Authors and Affiliations
Contributions
S.S., S.T., L.C., E.S. contributed equally to this work. S.K.S. and E.S.I. conceived the project. K.B., S.S., S.T., L.C., and E.S. generated the variants, performed the experiments and analyzed the results, G.B.L. analyzed VarCall data. S.R. prepared BAC DNA, performed Southern and Western blotting. V.M. wrote the imageJ script for cell survival analysis. G.B.L. and E.I. developed and tested the VarCall models. K.B., E.I., and S.K.S. analyzed and interpreted the data. K.B. and E.S.I. prepared the figures. K.B., E.S.I., and S.K.S. wrote the paper. All authors commented on the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Biswas, K., Lipton, G.B., Stauffer, S. et al. A computational model for classification of BRCA2 variants using mouse embryonic stem cell-based functional assays. npj Genom. Med. 5, 52 (2020). https://doi.org/10.1038/s41525-020-00158-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41525-020-00158-5
This article is cited by
-
Molecular profiling of BRCA1 and BRCA2 genes in Turkish patients with early-onset breast cancer
Egyptian Journal of Medical Human Genetics (2023)
-
An integrative model for the comprehensive classification of BRCA1 and BRCA2 variants of uncertain clinical significance
npj Genomic Medicine (2022)
-
BRCA2-DSS1 interaction is dispensable for RAD51 recruitment at replication-induced and meiotic DNA double strand breaks
Nature Communications (2022)
