
Abstract
Living organisms process information to interact and adapt to their surroundings with the goal of finding food, mating, or averting hazards. The structure of their environment has profound repercussions through both selecting their internal architecture and also inducing adaptive responses to environmental cues and stimuli. Adaptive collective behavior underpinned by specialized optimization strategies is ubiquitous in the natural world. We develop a minimal model of agents that explore their environment by means of sampling trajectories. The spatial information stored in the sampling trajectories is our minimal definition of a cognitive map. We find that, as cognitive agents build and update their internal, cognitive representation of the causal structure of their environment, complex patterns emerge in the system, where the onset of pattern formation relates to the spatial overlap of cognitive maps. Exchange of information among the agents leads to an order-disorder transition. As a result of the spontaneous breaking of translational symmetry, a Goldstone mode emerges, which points at a collective mechanism of information transfer among cognitive organisms. These findings may be generally applicable to the design of decentralized, artificial-intelligence swarm systems.
Similar content being viewed by others

Introduction
The collective behavior of simple agents can exhibit a stunning degree of organization, as can be seen in the emergence of a mound from a cell colony of Dictyostelium discoideum, the construction of a complex termitarium by a termite colony, or the successful defense against predators by swarming starlings or a school of fish. Although the individual agents respond to environmental stimuli in a local, individual, and in most cases unconscious manner, the result often appears as beautifully orchestrated. Such phenomena naturally prompt the general question what are the features of such ‘intelligent’ collective behavior in a society of individuals with rather limited individual cognitive abilities.
It is therefore of great interest to investigate the impact of the cognitive competence of individual actors on their collective behavior from a fundamental point of view. This requires the definition of notions of cognition which are at the same time sufficiently general to resemble the wide class of agents encountered in collective phenomena, but at the same time are sufficiently simple to be accessible to statistical physics methodology. In search for such a minimal model, we observe that the navigation of agents through their environment requires a feedback loop of information processing, inference, and active response1,2,3. Survival requires living organisms to constantly incorporate information of their environment into some kind of internal representation of the exterior4. This internal representation can be as sophisticated as a human’s ability to navigate a complex metropolitan road network, or more rudimentary like the map-like spatial memory in the navigation of honey bees5,6,7,8,9.
A cognitive agent must be able to predict future events1. Picture a gazelle trying to evade a pursuing lion. Drawing on its knowledge of its immediate surroundings, the prey will choose a path leading to, for example, open space with multiple possibilities of escape, rather than a path leading to a cul-de-sac. As another example —particularly accessible to formal modeling— we may consider a chess player, whose activities take place in the abstract space of moves on the chessboard. It is the player’s internal cognitive map that allows her to contemplate the possible moves and the ramifications of their consequences. Depending on the experience and skills of the player, she will be able to contemplate her possible next move, her opponent’s countermove, and possibly additional moves in response. The player, in other words, will sample hypothetical sequences of steps (i.e. trajectories) in the abstract space of moves within the chessboard.
The player’s strategy can be cast into a simple, general form: the maximization of future options to move without losing the king. The number of moves the player is able to contemplate ahead is a direct numerical measure of her cognitive competence. In the present study, we adopt a straightforward generalization of this measure by defining cognitive competence as the ability of an agent to determine the number of possible moves within a given environment. This ability depends upon the agent’s cognitive map, and we may assume that, similarly to the chess player, the agent will seek to maximize its number of future options to move.
We will now describe a mechanistic implementation of the above ideas which has the twofold advantage to (i) make our ideas concrete, and (ii) provide a connection to the field of active matter10,11. We consider a set of freely mobile, identical, spherical particles with diameter σ. Their only ‘cognitive’ activity is to explore the surrounding space. This exploration is performed via hypothetical random walks of a certain length, starting from the agent’s current position, and by evaluating the shape of such walks they gain knowledge about the location of other particles or confining boundaries. More precisely, each agent performs a fixed number Nω of such walks and evaluates how elongated the hypothetical trajectory of this walk is, thus allowing the inference of the location of confining objects, where the trajectory is likely to be more compact, and empty areas, where the trajectory can be more elongated and spacious. As measure for quantifying the configuration of each hypothetical trajectory we use the radius of gyration (see Methods). Clearly, the larger the cognitive competence of the agent is (i.e. the longer these hypothetical walks can be made), the larger the cognitive map of the environment will be.
A formal analogy between random walks and ideal polymers12,13 can help us understand what to expect. If the random walks were really executed, with no crossings allowed, the resulting interaction would be analogous to the repulsion experienced between star-copolymer molecules with nω chains. The mutual interaction of polymer chains is known to be characterized by isotropically repulsive entropic forces14. We will demonstrate below that by replacing the real random walks with hypothetical, sampling walks, hence introducing cognitive maps into the system, the collective behavior changes dramatically.
For each agent, we consider a set of random, hypothetical sampling trajectories, {Γτ(t)}, each of total duration τ, that the agent may traverse to explore its environment. Following an earlier work where these hypothetical walks have been introduced15, we explicitly indicate the dependence on time t because the cognitive map is dynamically updated as information is acquired. Starting from its initial position, r0, the region probed by the agent, and thus the size of its cognitive map, is directly proportional to τ.
We can build a probabilistic description of this cognitive map by considering the probability density function P(Γτ(t)|r0) associated to an ensemble of trajectories all starting from r0. Our probabilistic description should however represent mathematically the information acquired in building a cognitive map. According to Shannon16,17, −PlnP is the most general functional form that obeys the constraints of continuity, nonnegativity, and additivity of information. It is then natural to express the information content stored in the cognitive map as
which is a path integral over the hypothetical trajectories of an agent at position r, building up the cognitive map {Γτ(t)} (see Methods and ref. 15,18), and where kB is Boltzmann’s constant to give dimensions of entropy.
The central assumption of the present work shall be that intelligent agents tend to maximize the information content stored in their cognitive maps. This assumption, together with Eq. (1), immediately implies that a cognitive agent tends to maximize the diversity of possible future trajectories. As a cognitive agent acquires information about the external environment, which is by nature of the process limited and partial, the most unbiased decision the agent can make is the one corresponding to the maximum of entropy, because it uses all the available information without any additional assumptions. Mathematically, it assigns a positive weight to every situation which is not excluded by the given information19,20.
Maximization of \({\mathscr{S}}\) can then be represented by a force acting on the agent of the form
where the coupling parameter θ (with dimensions of temperature) quantifies the cognitive competence of the agent, that is, how strongly the agent responds to the environment (see Methods). In order to maximize the information content of the cognitive map, an agent will move by following the gradient of \({\mathscr{S}}\).
An intuitive understanding of the principle stated above can be gained by considering again the predator-prey system discussed above. The prey will choose a path which maximizes the future available options (and hence its survival probability). More formally, the approach presented here is indebted to a number of contributions in complex system theory. The well-informed reader will recognize echoes of Kauffman’s hypothesized ‘fourth law of thermodynamics’21, stating that autonomous agents maximize the average secular construction of diversity21, e.g. organisms tend to increase the diversity of their organization. In the context of information-processing systems, related approaches have been expressed by Linsker22 with his “Infomax” principle which was used to demonstrate the emergence of structure in models of neural architecture23,24,25, or Ay et al.26 with the maximum of a predictive information —a relation between future states and past ones— biological infotaxis2, sensorimotor systems27, and control theory15. Our approach is based on the idea that cognitive systems entail some mechanism of prediction28,29. We therefore consider a finite duration τ of the hypothetical trajectories.
The motivation for our approach is that an optimal information-processing dynamics should indicate the level of competence of the agent to respond to complex stresses and stimuli. To name only a few examples where maximization of information or entropy has been found empirically and might constitute a fundamental mechanism, maximization of information has been measured as a characteristic of human cognition30,31; a pair-wise maximum entropy accurately models resting-state human brain activity32; patients with ADHD exhibit reduced signal entropy as compared with healthy individuals33.
Figure 1 shows a schematic of a few agents moving on a two-dimensional space, whereas the vertical dimension represents time. Agents interact with each other and with the environment. Each agent explores the available configuration space and acquires information about its structure, and in so doing builds its cognitive map, and optimizes its behavior through responding to the surrounding. The hypothetical trajectories, exploring the available space, have an envelope characterized by a spatial extension λ, and temporal extension τ. In the overlap regions of the forward cones the agents have a probability to collide. This possibility gives rise to the effective force F(r; τ). The overlap regions and the corresponding effective forces appear when the distance between any two agents becomes shorter than the average linear length of the agents’ hypothetical trajectories, which relates to the size of the cognitive map.

Schematic representation of a system of cognitive agents and their cognitive maps. (a) Starting from the initial condition in configuration space the agents (empty circles) create a cognitive map of their surroundings by means of hypothetical sampling trajectories of duration τ. The cones show a (2 + 1)-dimensional envelope of the trajectories, which represent the cognitive maps, of average radius λ. When the cones overlap, the agents sense each other and a force arises. (b) Shown here are four sampling trajectories emanating from cognitive agent i. As one of the trajectories impacts with agent j, agent i is forced to modify its trajectory, thus responding to its cognitive representation of the environment. Cognitive competence is the tendency to maximize the options left after one agent enters the space of the other, and to avoid in the most efficient way the overlapping regions.
Our definition of information entropy \({\mathscr{S}}\) satisfies the following criteria. First, \({\mathscr{S}}\) is based on the information content of the system because agents retrieve and process information about the presence of other agents. Second, it does not require any specific goal or strategy, such as rules for taxis of bacteria in chemo-attractant concentration fields. Third, it obeys the laws of information theory and information processing, essential to build cognitive maps. Fourth, it obeys causality because the current state of the cognitive map influences the agent’s future dynamics.
Results
We carried out simulations of N identical agents in a two-dimensional, continuous system of size L×L, where agents interact with each other via the cognitive force F and via hard-core repulsion when their distance is less than the agent’s diameter σ. The agents’ configurations evolve continuously from a random initial distribution towards steady-state configurations for different sizes λ of the cognitive map. We define the size of a cognitive map as the average distance between start and end of hypothetical trajectories \(\lambda =\frac{1}{{N}_{{\rm{\Omega }}}}{\sum }_{n=1}^{{N}_{{\rm{\Omega }}}}\,|{{\bf{r}}}_{{{\rm{\Gamma }}}_{n}}(\tau )-{{\bf{r}}}_{{{\rm{\Gamma }}}_{n}}(0)|\), where NΩ is the total number of hypothetical sampling trajectories.
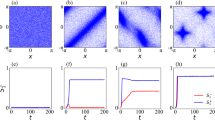
Figure 2 shows the steady-state configurations of the system as the size λ of the map increases. At low values of cognitive map size λ with respect to the inter-agent separation, most agents are isolated and randomly distributed throughout the system (Fig. 2a). The agents try to stay as far apart as possible from each other in an attempt to maximize their available space. For a horizon of linear size λ, the available space scales as λ2. As λ increases, we observe the spontaneous formation of short linear chains of agents (Fig. 2b). At λ = 5.6σ, the chains grow longer and outline a labyrinthine pattern in the system (Fig. 2c). The emergence of this spatial organization can be understood as a way to increase the available configuration space in the direction normal to the chain-like structures. Consider chains of typical length \(\ell \). Once chains are formed, the space available to their horizons scales approximately as \(\ell \lambda \). Thus, the ratio of available space between chains and the disordered configuration scales approximately as \(\ell /\lambda \). The agents can therefore increase their available space by increasing \(\ell \), and forming long chains.

Steady-state configurations of a cognitive-agent system. Snapshots of a two-dimensional system with filling fraction ϕ = 0.1 (N = 800, L = 80σ) in steady-state configurations. As the size of the cognitive map λ increases, complex structures emerge. (a) At λ = 0.8σ the agents are randomly distributed. (b) At λ = 3.2σ agents start forming short linear chains. (c) At λ = 5.6σ the chains outline a labyrinthine pattern. (d) At λ = 7.6σ the labyrinthine pattern continuously changes into a cellular structure. At λ = 10σ (e) and λ = 10.8σ (f) the cellular structure is well formed. Thus, cognitive agents capable of ‘intelligent’ response to their environment and maximizing their cognitive map information exhibit a clear phase transition from disorder (at small λ) to order (at large λ).
Upon further increase of λ, the pattern continuously turns into a cellular structure (Fig. 2d,e), which we find well developed at λ = 10.8σ (Fig. 2f). Consider now the (entropically) advantageous strategy of agents to form chains (e.g. for λ = 5.6σ). With increasing λ agents tend to arrange such that they keep larger distances from other chains of agents within proximity. Due to the fixed filling fraction and size of the system this leads to chains connecting to joints and ultimately cellular structures, of roughly hexagonal symmetry, which provides the optimal tiling of the plane.
A similar sequence of patterns can be observed when we vary the filling fraction, ϕ ≡ Nπσ2/(4L2). The phase diagram of the system is shown in Fig. 3a. The transition line from short chains to more complex patterns is well fitted by a relation \(\varphi \sim {\lambda }^{-2}\) which suggests that the transition is triggered as the mean inter-agent distance becomes comparable to the cognitive map size λ.

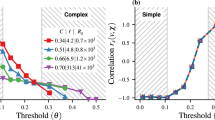
Nonequilibrium phase diagram of the cognitive agent system. (a) Symbols represent the steady-state configuration for up to N = 500 agents in a system of size L = 60σ: isolated agents (●), short chains (⚬), labyrinthine pattern (+), cellular pattern (□). Heat map of the anisotropy \(\alpha \equiv \frac{{\beta }_{1}-{\beta }_{2}}{{\beta }_{1}+{\beta }_{2}}\) of the \({W}_{2}^{\mathrm{1,1}}\) Minkowski tensor. The dotted line represents the ϕ−1/2 scaling of the transition values of λ (note that an offset is added because at very low filling fraction no transition is expected as there is now significant overlap of the cognitive maps). (b) Dependence of the anisotropy \(\alpha \equiv \frac{{\beta }_{1}-{\beta }_{2}}{{\beta }_{1}+{\beta }_{2}}\) on the cognitive map size λ for a system at ϕ = 0.1 (N = 800, L = 80σ). Symbols have the same meaning as in panel (a). Cognitive agents exhibit an order-disorder phase transition to a cellular pattern as the mean inter-agent distance becomes comparable to the cognitive map size λ. The arrows indicate the values of λ for the configurations shown in Fig. 2.
In order to analyze the complex morphology of the patterns, we employ the anisotropy parameter \(\alpha \equiv \frac{{\beta }_{1}-{\beta }_{2}}{{\beta }_{1}+{\beta }_{2}}\), defined in terms of the eigenvalues β1 and β2 of the Minkowski tensor34,35, which is a measure of anisotropy of configurations of particles (see Methods for more details). Figure 3a shows as a heat map the association of the phase diagram with the anisotropy α of the configurational patterns. At fixed filling fraction ϕ, the system exhibits the largest anisotropy α when linear chains start to connect with each other for intermediate values of the size λ of the cognitive map. In contrast, at low λ, where agents are isolated, the system is trivially isotropic. At large values of λ, where cognitive maps significantly overlap and cellular patterns emerge (Fig. 2f), the associated anisotropy decreases to values that are however larger than in the case of low λ. This indicates that the system gains again isotropy on the larger scale of the cells. Figure 3b shows the anisotropy α of the pattern. It exhibits a sharp maximum at \(\lambda \simeq 5.5\sigma \) where the linear chains are most pronounced and the system is at the threshold of forming the labyrinthine patterns. The transition from isolated particles to cellular structures appears to be continuous, as no structural or dynamical observable shows discontinuous behavior. The transition occurs when α is considerably larger than zero, that is, for \(\lambda \simeq 2\sigma \).
Our results so far illustrate that as the cognitive maps of the agents overlap, interesting collective behavior emerges. A moment’s reflection will show that agents perceive each other’s presence via their respective cognitive maps, and thus information about each other’s presence must be exchanged, and this information flow, in turn, dynamically modifies the cognitive maps of the agents. Quantifying the information flow among agents will instruct us on the origin of the collective behavior.
This information flow can be quantified via the notion of mutual information36,37,38,39,40,41,42. The mutual information for two random variables a and b is given by \({\sum }_{a,b}\,P(a,b){\mathrm{log}}_{2}\frac{P(a,b)}{P(a)P(b)}\), where P(a) represents the probability distribution of a, and P(a, b) is the joint probability distribution. Because we are interested in isolating the causal interaction between agents that underpins the update of the cognitive maps, we consider the positions (xi(t), yi(t)) of the i-th agent at time t and compute \({\overrightarrow{M}}_{ij}\equiv ({M}_{ij}^{x},{M}_{ij}^{y})\), between agent i and j, where \({M}_{ij}^{x}=P({x}_{i},{x}_{j}){\rm{l}}{\rm{o}}{{\rm{g}}}_{2}\frac{P({x}_{i},{x}_{j})}{P({x}_{i})P({x}_{j})}\), and \({M}_{ij}^{y}=P({y}_{i},{y}_{j}){\mathrm{log}}_{2}\frac{P({y}_{i},{y}_{j})}{P({y}_{i})P({y}_{j})}\). The total mutual information is then
where 〈i, j〉 represent all pairs of agents which are within a local neighborhood of distance 4σ (larger values of this cutoff do not qualitatively change the results), and Np is the total number of neighbor pairs (i, j) included in the sum in Eq. (3).
Figure 4(a) shows the dependence of the mutual information \( {\mathcal M} \) on the size of the cognitive map λ. At very small λ, the cognitive agent system exhibits a mutual information which is nearly vanishing on account of the nearly independent motion of each agent. As the size of the cognitive map increases beyond \(\lambda \simeq 2.0\sigma \), \( {\mathcal M} \) increases steadily, while the system develops labyrinthine and cellular patterns. At \(\lambda \simeq 9.5\sigma \), \( {\mathcal M} \) reaches a plateau value, corresponding to well-developed cellular patterns. These results show that upon increasing the size of the cognitive maps, an indirect exchange of information takes place among the agents, which in turn leads to the formation of complex structures.

Mutual information as an order parameter in the transition of cognitive agents. As the size of the cognitive map λ increases, the mutual information \( {\mathcal M} \) among the cognitive agents increases once their maps overlap significantly. The calculations of the mutual information \( {\mathcal M} \) depending on λ were done for a system of size L = 80σ at fixed number density. The results are averaged over eight independent simulations for each data point. The small arrows on the top abscissa axis indicate the values of λ for the configurations shown in Fig. 2, whereas the large black and red arrows mark the location of the systems considered in Fig. 6.
The information exchange among the agents is correlated to their structural transition. To quantify the degree of correlated motion, we turn to a standard tool for the analysis of the dynamic response of many-body systems43: the displacement covariance matrix44 Cij ≡ 〈δri(t)⋅δrj(t)〉t, where δri(t) ≡ ri(t) − 〈ri〉, and the angle brackets with subscript t indicate an average over time; the eigenvalues and eigenvectors of Cij provide information about the coherent motion in the system. Provided that the particles have well-defined average positions 〈ri〉 —and this is in fact the case once complex patterns emerge— the spectral properties of Cij can describe effective excitation modes45.
Figure 5a shows the eigenvalues of Cij for δx and δy, and the comparison with the uncorrelated motion generated with a random matrix model of Gaussian-distributed displacements. The first mode of the cognitive system is considerably above the random Gaussian model, and corresponds to a large wavelength mode propagating through the system. This collective mode is shown in Fig. 5b. This is the Goldstone mode associated to the structural transition and corresponds to excitations of the ordered state. The situation is reminiscent of equilibrium systems where the spontaneous breaking of translational symmetry (Galilean invariance) is associated with the emergence a massless Goldstone mode, propagating through the system with a scale-free correlation length. Goldstone modes have been also identified in models and observations of active collective behavior46,47,48. In practice, this means that in certain configurations of the system some fluctuations propagate very quickly throughout the system, and they do not depend on the system size.

Growth of correlated motion. (a) Spectrum of eigenvalues of the displacement covariance matrix (for a system with ϕ = 0.1 (N = 200, L = 40σ) and λ = 8σ) and comparison with a model of Gaussian-distributed random displacements. The largest eigenvalue mode corresponds to a Goldstone mode propagating through the system. (b) We show the collective fluctuation in the agents’ positions due to a Goldstone mode propagating through the system when elongated linear chain patterns emerge. As complex patterns emerge and Galilean invariance is spontaneously broken, collective fluctuations materialize through the propagation of a Goldstone mode.
Figure 6 shows the spatial correlation of displacements between agents defined via the correlation function G(d) = 〈δri(t)⋅δrj(t)〉t,(i,j), where d ≡ |ri(t) − rj(t)|, and the angle brackets with subscript t, (i, j) indicate an average over time and pairs of agents (i, j) separated by distance d. The correlation in the agents’ motion decays with distance with a power law (the oscillations with decaying amplitudes are due to the cellular pattern of the system).

Spatial correlations. The correlation G(d) in the motion of N = 800 (L = 80σ, ϕ = 0.1) agents. G(d) exhibits a long-range nature, compatible with the presence of long-range excitation in a system with symmetry breaking. The oscillation superimposed to the decay of G(d) is due to the cellular pattern of the system.
In summary, our study furnishes a first step forward in the understanding of nonequilibrium transitions in a system of cognitive agents that dynamically interact with their environment, and respond to it with cognitive competence by maximizing the information content of their cognitive maps. The transition from isolated particles to complex patterns is characterized by different degree of overlap of the cognitive maps. The continuous change of \( {\mathcal M} \) as the system develops complex patterns, together with the change of the anisotropy parameter \(\frac{{\beta }_{1}-{\beta }_{2}}{{\beta }_{1}+{\beta }_{2}}\) point at a transition in cognitive-agent systems. We have identified a Goldstone mode propagating through the system that is generated by the spontaneous symmetry breaking of the structural transition as complex patterns emerge.
Apart for its significance for investigations of complex organisms whose active response to environmental stimuli is based on various levels of cognition, from eusocial insects to mammals, our results are relevant to artificial systems like autonomous micro-robots, and swarm robotics49,50, which are explicitly designed to autonomously mimic the collective behavior of living organisms.
Methods
Simulations
Every agent obeys the following equation of motion
where v is the velocity of the agent, m its mass, γ the viscous drag, F(r;τ) the cognitive force, and h(r) is the short-range repulsion among agents, modeled via a repulsive linear spring when |ri − rj| < σ, where σ is the hard-core diameter of the agents.
As described above, the calculation of the cognitive force F(r;τ) [Eq. (2)] requires calculating a set of hypothetical sampling trajectories {Γτ(t)}. The simulation algorithm is based on the following two steps: (i) generation of the hypothetical trajectories, resulting in the construction of the cognitive map, and computation of the cognitive force F(r;τ) (see below for details); (ii) update of the agent’s position according to Eq. (4). During the generation of the hypothetical trajectories, all agents in the system remain fixed in their current positions. The dynamics of the system evolve by repeating the two steps above.
The agents are initially placed randomly with a uniform distribution within the system and without any overlap of the agents’ hard cores. The system size is, unless otherwise specified, fixed at L = 80σ.
Construction of the cognitive map
The calculation of P(Γτ(t)|r0) is performed by generating hypothetical sampling trajectories, each of which represents a virtual evolution during the time [0,τ] of the agent with constraints fixed at the present configuration and not depending on time. The hypothetical trajectories are generated using Langevin dynamics
where v, m, γ, and h(r) have the same meaning as in Eq (4), ξ(t) is a random noise with zero mean and 〈ξi(t)ξj(t′)〉 = 2γkBTδijδ(t − t′).
Any interaction of a hypothetical sampling trajectory with another agent is hard-core repulsive, that is the trajectory is reflected elastically by the other agent.
Derivation of the cognitive force
Here we show the derivation of an expression for the entropic force we use to calculate the system’s dynamics. This is a derivation adapted and simplified from15. We start by using Eqs (1) and (2) and consider the gradient in (2) with respect to position space coordinates at present time r(t = 0) = r(0) and arrive at
We can assume deterministic behavior within one small sub-interval [t, t + ε]. Therefore a conditional path probability can be decomposed into the probabilities of its intervals in the following way:
where Γε denotes a path of length ε and τ = Nε. Accordingly, we can express the gradient of the probability as
Since Γε can be seen as the path from r(0) to r(ε) in one step, the gradient in probability of jumping from r(0) to r(ε) with respect to r(0) is equal to the negative gradient in probability of jumping from r(0) to r(ε) with respect to r(ε):
By Taylor expanding the position r(ε) we find
where f(t) denotes a random Gaussian force with
and where δ(t) is the Dirac δ-distribution, and δij is the Kronecker delta.
Because these are equilibrium, Brownian trajectories, for very short times the probability distribution of the displacements is Gaussian in r(ε)
Using this last result Eq. (9) takes the form
Plugging this last equation in Eq. (6) we obtain
To estimate the probabilities Pr(Γτ|r(0)) we use NΩ Brownian trajectories exploring the available space for a finite time (horizon) τ. Every sampling trajectory starts from the current system state r(0). We assign a uniform probability for all paths within a neighborhood of a sampled path based on the volume Ωn explored \({\rm{\Pr }}({{\rm{\Gamma }}}_{\tau ,n}|{\bf{r}}\mathrm{(0))}{\mathscr{D}}{{\rm{\Omega }}}_{n}^{-1}\). From the normalization condition we find
Thus, our estimate of the force in Eq. (15) is
Finally, by adding a vanishing term, we find
The volume of every trajectory is defined as \({{\rm{\Omega }}}_{n}^{-1}={N}_{{\rm{\Omega }}}P({{\rm{\Gamma }}}_{\tau }(t)|{{\bf{r}}}_{0})\), and we approximate it through the radius of gyration R of all K positions of the sampling trajectory relative to their mean position \({{\rm{\Omega }}}_{n}\approx {R}^{2}=\frac{1}{K}{\sum }_{k\mathrm{=1}}^{K}\,{({{\bf{r}}}_{k}-\bar{{\bf{r}}})}^{2}\).
Measure of anisotropy
The Minkowski tensor \({{\bf{W}}}_{2}^{\mathrm{1,1}}(C)\equiv \frac{1}{2}{\int }_{\partial C}\,{\bf{r}}\odot {\bf{n}}\,{G}_{2}\,dr\) provides a measure of anisotropic morphologies34,35. It is a second rank symmetric tensor, where G2 = (κ1 + κ2)/2 is the local curvature, r the position vector, n the normal vector to the surface ∂C of a body, and \({(a\odot b)}_{ij}\equiv ({a}_{i}{b}_{j}+{a}_{j}{b}_{i})/2\) is the symmetric tensor product of vectors a and b. The anisotropy parameter \(\alpha \equiv \frac{{\beta }_{1}-{\beta }_{2}}{{\beta }_{1}+{\beta }_{2}}\), where β1 and β2 are the largest and smallest eigenvalues of \({{\bf{W}}}_{2}^{\mathrm{1,1}}\), respectively, gives a measure of anisotropy of the pattern.
References
Schultz, W., Dayan, P. & Montague, P. R. A neural substrate of prediction and reward. Science 275, 1593–1599 (1997).
Vergassola, M., Villermaux, E. & Shraiman, B. I. ‘Infotaxis’ as a strategy for searching without gradients. Nature 445, 406–409 (2007).
Torney, C., Neufeld, Z. & Couzin, I. D. Context-dependent interaction leads to emergent search behavior in social aggregates. Proc. Natl. Acad. Sci. USA 106, 22055–22060 (2009).
Gallistel, C. R. Animal cognition: The representation of space, time and number. Ann. Rev. Psychol. 40, 155–189 (1989).
Real, L. A. Animal choice behavior and the evolution of cognitive architecture. Science 253, 980 (1991).
Kamil, A. C. & Jones, J. E. The seed-storing corvid clark’s nutcracker learns geometric relationships among landmarks. Nature 390, 276–279 (1997).
Menzel, R. et al. Honey bees navigate according to a map-like spatial memory. Proc. Natl. Acad. Sci. USA 102, 3040–3045 (2005).
Couzin, I. Collective minds. Nature 445, 715–715 (2007).
Normand, E. & Boesch, C. Sophisticated Euclidean maps in forest chimpanzees. Animal Behaviour 77, 1195–1201 (2009).
Marchetti, M. C. et al. Hydrodynamics of soft active matter. Rev. Mod. Phys. 85, 1143–1189 (2013).
Elgeti, J., Winkler, R. G. & Gompper, G. Physics of microswimmers–single particle motion and collective behavior: a review. Rep. Prog. Phys. 78, 056601 (2015).
Edwards, S. F. The statistical mechanics of polymers with excluded volume. Proc. Phys. Soc. 85, 613 (1965).
De Gennes, P.-G. Some conformation problems for long macromolecules. Rep. Prog. Phys. 32, 187 (1969).
Doi, M. Introduction to polymer physics (Oxford University Press, 1996).
Wissner-Gross, A. D. & Freer, C. E. Causal entropic forces. Phys. Rev. Lett. 110, 168702 (2013).
Shannon, C. E. A mathematical theory of communication. Bell System Tech. J. 27, 379–423 (1948).
Shannon, C. E. & Weaver, W. The mathematical theory of communication (University of Illinois Press, 1949).
Martyushev, L. M. & Seleznev, V. D. Maximum entropy production principle in physics, chemistry and biology. Phys. Rep. 426, 1–45 (2006).
Jaynes, E. T. Information theory and statistical mechanics. Phys. Rev. 106, 620–630 (1957).
Bialek, W. et al. Statistical mechanics for natural flocks of birds. Proc. Natl. Acad. Sci. USA 109, 4786–4791 (2012).
Kauffman, S. A. Investigations (Oxford University Press, 2000).
Linsker, R. Self-organization in a perceptual network. Computer 21, 105–117 (1988).
Linsker, R. From basic network principles to neural architecture: emergence of spatial-opponent cells. Proc. Natl. Acad. Sci. USA 83, 7508–7512 (1986).
Linsker, R. From basic network principles to neural architecture: emergence of orientation-selective cells. Proc. Natl. Acad. Sci. USA 83, 8390–8394 (1986).
Linsker, R. From basic network principles to neural architecture: emergence of orientation columns. Proc. Natl. Acad. Sci. USA 83, 8779–8783 (1986).
Ay, N., Bertschinger, N., Der, R., Güttler, F. & Olbrich, E. Predictive information and explorative behavior of autonomous robots. Eur. Phys. J. B 63, 329–339 (2008).
Klyubin, A. S., Polani, D. & Nehaniv, C. L. Keep your options open: An information-based driving principle for sensorimotor systems. PLoS ONE 3, 1–14 (2008).
Leinweber, M., Ward, D. R., Sobczak, J. M., Attinger, A. & Keller, G. B. A sensorimotor circuit in mouse cortex for visual flow predictions. Neuron 95, 1420–1432 (2017).
Friston, K. The free-energy principle: a unified brain theory? Nature Rev. Neurosci. 11, 127–138 (2010).
Guevara Erra, R., Mateos, D. M., Wennberg, R. & Perez Velazquez, J. L. Statistical mechanics of consciousness: Maximization of information content of network is associated with conscious awareness. Phys. Rev. E 94, 052402 (2016).
Mateos, D. M., Wennberg, R., Guevara, R. & Perez Velazquez, J. L. Consciousness as a global property of brain dynamic activity. Phys. Rev. E 96, 062410 (2017).
Watanabe, T. et al. A pairwise maximum entropy model accurately describes resting-state human brain networks. Nature Commun. 4, 1370 (2013).
Sokunbi, M. O. et al. Resting state fMRI entropy probes complexity of brain activity in adults with ADHD. Psychiat. Res.: Neuroim. 214, 341–348 (2013).
Schröder-Turk, G., Kapfer, S., Breidenbach, B., Beisbart, C. & Mecke, K. Tensorial minkowski functionals and anisotropy measures for planar patterns. Journal of Microscopy 238, 57–74 (2010).
Schröder-Turk, G. E. et al. Minkowski tensors of anisotropic spatial structure. New Journal of Physics 15, 083028 (2013).
Fraser, A. M. & Swinney, H. L. Independent coordinates for strange attractors from mutual information. Phys. Rev. A 33, 1134–1140 (1986).
Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 85, 461–464 (2000).
Wicks, R. T., Chapman, S. C. & Dendy, R. O. Mutual information as a tool for identifying phase transitions in dynamical complex systems with limited data. Phys. Rev. E 75, 051125 (2007).
Vanni, F., Luković, M. & Grigolini, P. Criticality and transmission of information in a swarm of cooperative units. Phys. Rev. Lett. 107, 078103 (2011).
Mora, T. & Bialek, W. Are biological systems poised at criticality? J. Stat. Phys. 144, 268–302 (2011).
Luković, M., Vanni, F., Svenkeson, A. & Grigolini, P. Transmission of information at criticality. Physica A 416, 430–438 (2014).
Melzer, A. & Schella, A. Symbolic transfer entropy analysis of the dust interaction in the presence of wakefields in dusty plasmas. Phys. Rev. E 89, 041103 (2014).
Ashcroft, N. W. & Mermin, N. D. Solid state physics (Holt, Rinehart and Winston, New York, 1976, 2005).
Henkes, S., Brito, C. & Dauchot, O. Extracting vibrational modes from fluctuations: a pedagogical discussion. Soft Matter 8, 6092–6109 (2012).
Brito, C., Dauchot, O., Biroli, G. & Bouchaud, J.-P. Elementary excitation modes in a granular glass above jamming. Soft Matter 6, 3013–3022 (2010).
Toner, J., Tu, Y. & Ramaswamy, S. Hydrodynamics and phases of flocks. Annals of Physics 318, 170–244 Special Issue (2005).
Cavagna, A. et al. Scale-free correlations in starling flocks. Proc. Natl. Acad. Sci. USA 107, 11865–11870 (2010).
Bialek, W. et al. Social interactions dominate speed control in poising natural flocks near criticality. Proc. Natl. Acad. Sci. USA 111, 7212–7217 (2014).
Şahin, E. Swarm robotics: From sources of inspiration to domains of application. In International workshop on swarm robotics, 10–20 (Springer, 2004).
Brambilla, M., Ferrante, E., Birattari, M. & Dorigo, M. Swarm robotics: a review from the swarm engineering perspective. Swarm Intell. 7, 1–41 (2013).
Acknowledgements
We gratefully acknowledge discussions with Giovanni Ciccotti, Mirko Lukovic, Agostina Palmigiano, and André Schella.
Author information
Authors and Affiliations
Contributions
M.G.M. conceived the project. H.H. developed the code and carried out the simulations. All authors performed the analysis, discussed and wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hornischer, H., Herminghaus, S. & Mazza, M.G. Structural transition in the collective behavior of cognitive agents. Sci Rep 9, 12477 (2019). https://doi.org/10.1038/s41598-019-48638-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-48638-8
This article is cited by
-
Controlling inter-particle distances in crowds of motile, cognitive, active particles
Scientific Reports (2024)
-
Deploying digitalisation and artificial intelligence in sustainable development research
Environment, Development and Sustainability (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
