
Abstract
Since the 2019 novel coronavirus disease (COVID-19) outbreak in 2019 and the pandemic continues for more than one year, a vast amount of drug research has been conducted and few of them got FDA approval. Our objective is to prioritize repurposable drugs using a pipeline that systematically integrates the interaction between COVID-19 and drugs, deep graph neural networks, and in vitro/population-based validations. We first collected all available drugs (n = 3635) related to COVID-19 patient treatment through CTDbase. We built a COVID-19 knowledge graph based on the interactions among virus baits, host genes, pathways, drugs, and phenotypes. A deep graph neural network approach was used to derive the candidate drug’s representation based on the biological interactions. We prioritized the candidate drugs using clinical trial history, and then validated them with their genetic profiles, in vitro experimental efficacy, and population-based treatment effect. We highlight the top 22 drugs including Azithromycin, Atorvastatin, Aspirin, Acetaminophen, and Albuterol. We further pinpointed drug combinations that may synergistically target COVID-19. In summary, we demonstrated that the integration of extensive interactions, deep neural networks, and multiple evidence can facilitate the rapid identification of candidate drugs for COVID-19 treatment.
Similar content being viewed by others
Introduction
The emergence of SARS-CoV-2 (2019 novel coronavirus) has created the COVID-19 global pandemic. As of today (September 3, 2021), there have been over 219 million COVID-19 cases worldwide1. To prevent the COVID-19, several COVID-19 vaccines have received emergency approval2, and 3 billion dosages were administered. To treat the COVID-19, many research efforts are ongoing, and the FDA approved Remdesivir3 and Molnupiravir4 as the COVID-19 treatments. However, none of them has proved high effectiveness for COVID-195,6. Addressing the abundant needs to continue the COVID-19 drug development, many researchers have screened thousands of candidate therapeutic agents7,8. These agents can be divided into two broad categories: those that directly target the virus replication cycle, and those based on immunotherapy approaches either aimed to boost innate antiviral immune responses (e.g., targeting the host angiotensin-converting enzyme 2 (ACE2) that SARS-CoV-2 directly binds)9 or to alleviate damage induced by dysregulated inflammatory responses10. Research on the COVID-19 therapeutic agents has created valuable knowledge and data. For example, a curated list of potential COVID-19 therapeutics is available for research, such as Comparative Toxicogenomics Database (CTDbase), which have offered valuable resources for systematic integration of accumulated COVID-19 knowledge.
Drug discovery, however, is an expensive and time-consuming process. It typically takes many years and costs billions of dollars to develop and obtain the approval of a drug. Drug repurposing is to identify existing drugs or compounds that can be efficacious to other conditions of interest. Drug repurposing via systematic integration of pharmacodynamics, in vitro drug screening, and population-scale clinical data analysis carries high potential for a novel approach by identifying highly promising drugs and their combinations to save the cost and accelerate discovery11. Based on accumulated genomic and pharmacological knowledge, several computational approaches have explored and identified potentially effective drug and/or vaccine candidates12. Examples include a network pharmacology study in protein–protein interaction (PPI) network13, in silico protein docking14, and sequencing analysis15. Another family of studies has utilized retrospective analysis of clinical data, such as electronic health records (EHRs). These studies have assessed the potential efficacy of drugs including angiotensin receptor blockers, estradiol, or antiandrogens16. Although network pharmacology and retrospective clinical data analysis provide complementary insight into potential drugs, few studies have integrated these complementary perspectives, particularly in COVID-19. This work attempts to identify repurposable drugs from SARS-CoV-2-drug interactions and validating the drugs from retrospective in vitro efficacy and large-scale clinical data to prioritize repurposable drugs.
In this work, we innovated the traditional network analysis by deep graph neural representation to broaden the scope from local proximity to global topology. In traditional network analysis, network proximity is defined with explicit and direct interactions17, thus a node’s local role (e.g., neighbors, edge directions) and global position (e.g., overall topology or structure) are less considered. With the recent advancement in machine learning and representation learning, the graph neural network (GNN) approach is mature for the application of its state-of-the-art technology to network pharmacology. GNN is one field of deep neural networks that derive a vectorized representation of nodes, edges, or whole graphs. The graph node embedding can preserve the node’s local role and global position in the graph via iterative and nonlinear message passing and aggregation. It learns the structural properties of the neighborhood and the graph’s overall topological structure18. Adopting GNN into the biomedical network facilitates the integration of multimodal and complex relationships. Recently GNN has shown great promise in predicting interactions (e.g., PPIs, drug-drug adverse interactions, and drug-target interactions) and discovery of new molecules19. GNN can also benefit drug repurposing by representing the complex interaction between drugs and diseases. A recent attempt has been made to use the GNN for drug repurposing, which builds a general biomedical knowledge graph, called Drug Repurposing Knowledge Graph (DRKG), from seven biomedical databases and utilizes the embedding to discover a therapeutic association between drugs and diseases13. The knowledge graph includes 15 million edges across 39 different types connecting drugs, disease, genes, and pathways from seven databases including DrugBank, Hetionet, STRING, and a text-mining-driven database. This biomedical network representation offers a general and universal understanding of the interaction between drugs, genes, and diseases.
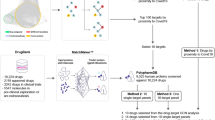
In this study, we built the COVID-19 knowledge graph from curated COVID-19 literature, transferred the universal representation from DRKG, and then utilized deep GNN to derive repurposable drugs’ representations which were rigorously validated with retrospective in vitro efficacy, reversed gene expression pattern, and large-scale EHRs (Fig. 1). Compared to the existing studies13,17, our work’s novelty can be summarized as: (i) deriving the COVID-19 knowledge representation on top of comprehensive biomedical knowledge graph, (ii) prioritizing the drug candidates based on multiple criteria including in vitro efficacy, population-based treatment effect, and reversed gene expression pattern, and iii) identifying synergistic drug combinations using complementary patterns.

Study workflow. (a) We collected 27 SARS-CoV-2 baits, 322 host genes interacting with baits, 1783 host genes on 609 pathways, 3635 drugs, 4427 drugs’ targets, and 1285 phenotypes, and their corresponding interactions from a curated list of COVID-19 literature in CTDbase. (b) We built the COVID-19 knowledge graph with nodes (baits, host genes, drugs,targets, pathways, and phenotypes) and edges (virus–host protein–protein interaction, gene–gene in pathways, drug-target, gene-phenotype, drug-phenotype interaction). (c) We derived the node’s embedding using the multi-relational and variational graph autoencoder20. We transferred extensive representation in DRKG using transfer learning. (d) We built a drug ranking model based on the drug’s embedding as features and clinical trials as silver-standard labels. (e) The drug ranking was validated using drug’s gene profiles, in vitro drug screening efficacy8, and large-scale electronic health records. (f) We presented validated drugs with their genetic, mechanistic, and epidemiological evidence. (g) Using the highly ranked drug candidates, we searched for drug combinations that satisfy complementary exposure patterns17.
Results
COVID-19 knowledge graph representation
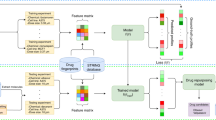
We first built a comprehensive COVID-19 knowledge graph that represents interactions between SARS-CoV-2 baits, host genes, pathways, targets, drugs (including experimental compounds), and phenotype (Fig. 1b, Methods 1). We then derived embedding for each drug, gene, phenotype, and SARS-CoV-2 bait using GNN. The GNN embedding method was the variational graph autoencoder with multi-relational edges (Methods 2)21. We internally validated the confidence of our knowledge graph embedding via link prediction (Methods 3). We compared the link prediction accuracy of our model with and without transfer learning using DRKG. Our node embedding showed high accuracy in predicting the relation in the COVID-19 knowledge graph. The initial DRKG universal embedding (without fine-tuning) achieved 0.5695 AUROC and 0.6431 AUPRC. After fine-tuning the DRKG embedding to the COVID-19 knowledge graph, we achieved AUROC 0.8121 and AUPRC 0.8524, respectively (Table S1), implying that the node embedding contains the local interaction (i.e., edges). We also visualized the node embedding using t-Distributed Stochastic Neighbor Embedding (t-SNE) (Method 3). We found that the node embedding of SARS-CoV-2 baits, host genes, drugs, and phenotypes were distributed separately (Fig. 2a, Fig. S2). We found that a group of antiviral and anti-inflammatory drugs (including Tenofovir, Ritonavir) was closely located to SARS-CoV-2 baits. Another group of anti-inflammatory and immunosuppressive drugs was highlighted including Cyclosporine and Dexamethasone, which were surrounded by genes related to inflammation and infection such as CD68 and PRDM1. We also found a group of anticoagulants (e.g., Heparin), anti-hypertensives (e.g., Amlodipine), anti-platelet (e.g., Dipyridamole), and anti-inflammatory drugs (e.g., Indomethacin). This t-SNE plot showed us that our node embedding captures global topology respecting common biological knowledge.


(a) COVID-19 knowledge graph t-SNE plot. Two nodes that have similar embedding are closely located in the t-SNE plot. We highlighted drugs undergoing clinical trials (as of July 23, 2020) to glimpse the promising repurposable drugs around the trial drugs. SARS-Cov-2 baits were the upper-left green hexagons. Genes, the gray triangles, were in the middle between baits and drugs. Drugs, the black rounds, were mixed with genes. Drugs undergoing clinical trials, the purple rounds, were closely located together. Phenotypes, the light brown diamonds, were closely located relevant genes and drugs. An interactive plot for a closer look is available in Fig. S2b–e we validated the drug ranking using four different external validation sources including. (b) Differentially expressed genes in SARS-CoV-2-infected human lung cells (GSE153970). (c) GSEA score between the infected human lung cell transcriptome and drug-induced transcriptome. (d) In vitro efficacy (e.g. % inhibition in viral entry and cytopathic effect assays8), and (e) treatment effects in EHRs. Figure (c) was created by Plotly22 (https://plotly.com/).
Initial drug ranking
Using the rich representation of the candidate drugs, we built an initial ranking model that predicts the drug’s antiviral effectiveness (Methods 4). The ranking model accuracy was AUROC between 0.77 and 0.90 and AUPRC between 0.17 and 0.25 (Table 1). The COVID-19 knowledge graph embedding that was boosted by general embedding from DRKG showed the highest accuracy, thanks to rich representation in DRKG. The higher AUROC/AUPRC indicated that the graph representation can encapsulate the underlying mechanism of drugs and the ranking model can pick out the drugs with potential efficacy.
Validation with multiple sources
From the initial drug ranking, we selected the top 300 highly-ranked drugs as potential repurposable candidates. We validated the highly-ranked drugs using a wide spectrum of validation sources such as genetic (Methods 5), retrospective in vivo (Methods 6), and epidemiological evidence (Methods 7), which reflects complementary aspects of drug effectiveness. Note that we did not exclude the clinical trial drugs that were used in the ranking model training.
Genetic validation using gene set enrichment analysis
For the genetic validation, we compared the gene expression signature profiles (Fig. 2b) of candidate drugs with that of SARS-CoV-2-infected host cells. We used gene set enrichment analysis (GSEA) to identify a significant association between SARS-CoV-2 and candidate drugs (Methods 5). As a result, we identified 183 statistically significant drugs including Gefitinib (enrichment scores or ES = − 0.70), Chlorpromazine (ES = − 0.70), Dexamethasone (ES = − 0.67), Rimexolone (ES = − 0.67), and Naltrexone (ES = − 0.64) (Fig. 2d). The lower ES scores of drugs mean the stronger signals in reversing the SARS-CoV-2 infected cell’s genetic profiles. The recall and precision was 0.3, which means our prediction has moderate accuracy when compared to genetic patterns.
Retrospective in vitro drug screening validation
We validated the candidates by comparing them with in vitro drug screening results retrospectively. We collected four different drug screening studies that target viral entry and viral replication/infection (Methods 6)7,8. As a result, the recall was between 0.21 and 0.44 and the precision was between 0.04 and 0.18 (Table 2), implying moderate accuracy in predicting efficacy in those selected drugs. Caution is needed in interpreting the accuracy here, because the number of overlapping drugs is limited in some studies and, thus, the statistical power is limited.
Population-based validation
We examined drugs administered to the COVID-19 patients and estimated treatment effects of the drugs in reducing the risk of mortality among hospitalized COVID-19 patients using Optum de-identified EHR database (Table S2, Fig. S3b, Methods 7). The EHRs had a total of 391 drugs used for COVID-19 hospitalized patients; 138 drugs were common in the EHRs and our initial 3,635 drugs. Ten (out of 138) drugs were effective (averaged treatment effect among treated or ATT > 0 and p-value < 0.05) in the EHRs (Fig. 2d). Among the ten positive drugs, our method identified six positive drugs (Table 2): Acetaminophen (ATT = 0.25), Azithromycin (ATT = 0.18), Atorvastatin (ATT = 0.17), Albuterol (ATT = 0.14), Aspirin (ATT = 0.14), and Hydroxychloroquine (ATT = 0.08) (Fig. 2e) (Table S3).
Validated high-ranked drugs
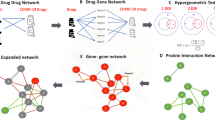
Based on the extensive validation, we presented top repurposable drugs after filtering out and re-ordering the drug candidates according to the existence of validating evidence. We used a data programming technique to combine the multiple pieces of evidence (Note S3)23. We highlighted the most promising drugs as follows (Fig. 3a). Due to limited space, we presented the top 21 drugs in Table 3 and the remaining drugs are available in Table S4. The top 21 drugs include anti-infection, immunosuppressive or immunomodulatory, antiviral, anti-fever, antihypertensive, anti-cancer drugs, anticoagulant drugs which all have different possible functions in inhibiting SARS-CoV-2 proliferation or reducing symptoms. We highlight them in the Discussion.

The interaction among virus baits, host preys, and drug targets. (a) Single drugs, (b) drug combinations. SARS-Cov-2 baits = green hexagons. Genes = gray triangles, Drugs = black rounds. The potentially repurposable drugs directly and indirectly target the host gene, which has PPI with the virus baits. Both figures are created by Cytoscape44. (https://cytoscape.org/).
Drug combination search
As indicated by the complexity of the COVID-19 interaction network, using single drugs to treat the viral infection might result in short term effects. To improve treatment efficacy, we further identified potential drug combinations from the top-ranking drugs with synergistic interactions without degradation in safety (Methods 8)42. We highlight the identified drug combinations as below (Table 4, Fig. 3b) and discuss potential mechanisms in discussion.
Discussion
The objective of this study is to prioritize repurposable drugs to treat COVID-19 by a novel pipeline which harmonizes several partial pieces of evidence. In this pipeline, we applied graph neural networks to transfer a general knowledge representation from a larger knowledge network and to optimize the general knowledge representation by a human-curated COVID-19 knowledge network. The optimized COVID-19 specific knowledge representation was applied to search and to prioritize the drugs similar to under COVID-19 trial drugs. After receiving those high-ranking drugs, we harmonize and validate those drugs' efficacy by GSEA scores, in vitro drug screening results, and population-based treatment effects. As a result, our proposed pipeline prioritized Azithromycin, Atorvastatin, Acetaminophen, and Aspirin. Also, we identified drug combinations with complementary exposure patterns: Etoposide + Sirolimus, Mefloquine + Sirolimus, Losartan + Ribavirin, and Hydroxychloroquine + Melatonin by complementary drug combination search. We highlight the identified drugs as follows:
Antimicrobial agents
Azithromycin and Teicoplanin can inhibit 23s ribosomes or RNA polymerase to stop the progress of infection. Some evidence supports Azithromycin regulating and/or decreasing the production of inflammatory mediators (IL-1β, IL-6, IL-8, IL-10, IL-12, and IFN-α), which might be effective to suppress viral entry24. Azithromycin targets ABCC1 (an inflammatory modulator) that has direct PPI with SARS-CoV-2 bait orf9c (Fig. 3a). The data imply that Azithromycin can be related to viral gene replication. In the population-based EHR validation, Azithromycin had the highest treatment effect, and it is currently under testing in a clinical trial(NCT04332107) to treat mild to moderate COVID-19 patients. Itraconazole can promote the production of IFN-1 that enhances viral-induced host responses39.
Immunosuppressive drugs
We identified immunosuppressive drugs such as Hydroxychloroquine, Chloroquine, and Sirolimus. Hydroxychloroquine or chloroquine are anti-parasite drugs but also have effects on toll-like receptors and ACE231, where toll-like receptors are associated with the production of inflammatory mediators (IL-1, IL-6, TNF-α, IFN-α, and IFN-\(\beta\))45, and ACE2 is the entry receptor of SARS-CoV-225. Hydroxychloroquine and chloroquine are rather controversial in terms of effectiveness46. Hydroxychloroquine directly targets PPT1, SIGMAR1, TRAF6, and SDC1, and it indirectly targets ECSIT and COL6A1, which had PPIs with SARS-CoV-2 baits orf8, orf9c orf10, and nsp6 (Fig. 3a). Thus, hydroxychloroquine might interfere with the SARS-CoV-2 replication. Sirolimus also works on toll-like receptors to treat COVID-1928.
Anti-inflammatory drugs
Acetaminophen directly targets ACADM, CPT2, and indirectly targets ACSL3, and MARK2 which finally have PPI with SARS-CoV-2 orf9b, M, and nsp7 (Fig. 3a). This means Acetaminophen may hinder the SARS-CoV-2 assembling and replication47. Aspirin deactivates platelet function48. A recent study reports that SARS-CoV-2 may over-activate platelets and thus reduce platelet production49. Considering this evidence, Aspirin might be effective in COVID-19 patients by suppressing platelet function and inflammatory processes. Celecoxib is a COX2 selective inhibitor. According to a consensus docking result, Celecoxib inhibits SARS-CoV-2 main protease up to 37%36.
Antiviral drugs
We identified various antiviral drugs such as Remdesivir, Lopinavir, and Tenofovir. Currently, Remdesivir has been proved to inhibit SARS-CoV-2 replication34. In terms of PPI between the virus bait and host prey, Lopinavir targets HMOX1, which is a host prey that binds with SARS-CoV-2 orf3a (Fig. 3a). A recent study reports that Tenofovir may prevent SARS-CoV-2 replication41.
Antihypertensive and lipid-lowering drugs
We identified Atorvastatin, Amlodipine, and Nifedipine. In addition to the original function for lowering cholesterol and triglyceride levels as an HMG-CoA reductase inhibitor, Atorvastatin can treat inflammation by lowering C-reactive protein (CRP)26. Elevated CRP is highly associated with the aggravation of non-severe COVID-19 adult patients50. Also, Atorvastatin directly targets PLAT and indirectly targets HDAC2, which is a host prey of the SARS-CoV-2 nsp5. The nsp5 can assist in releasing nsp4 and nsp16, which are involved in viral replication51. Both Nifedipine and Amlodipine are calcium channel blockers. Nifedipine reduces the ACE2 expression29. In a retrospective study, Amlodipine prevents virus replication in COVID-1952.
Anti-cancer, antipsychotic and hormone replacement drugs
Chlorpromazine, an antipsychotic drug shows an in vitro efficacy in inhibiting viral entry of SARS-CoV-238. Progesterone decreases the severity of cytokine storms in COVID-19 patients40. In addition to those proposed repurposing drugs, some other highly potential drugs are also worth considering such as Bilirubin53 and Decorin54.
We also propose the potential drug combinations as follows and present the possible mechanism.
Etoposide and sirolimus
Etoposide is an anti-cancer drug that targets DNA topoisomerase 2. A recent report proposes that Etoposide can also suppress the inflammatory cytokines in COVID-19, by reducing activated cytotoxic T cells that further lead to eliminate activated macrophages55. There are some clinical trials to test the effectiveness of sirolimus in COVID-19 patients (NCT04341675). There is a clinical trial to test the effectiveness of combining Sirolimus, Celecoxib, and Etoposide on cancer (NCT02574728). Based on the virus bait-host prey interactome, this combination’ targets interact with ten virus baits (including orf9c, orf8, orf3a, nsp1, nsp2, nsp5) without overlapping targets. We can infer this combination can be related to virus assembly in mitochondria due to an association with nsp251.
Mefloquine and sirolimus
Mefloquine not only treats malaria but also has some effects on the immune system56. The drug targets of Mefloquine and Sirolimus had similar baits-host prey interactome with Etoposide and Sirolimus.
Losartan and ribavirin
Losartan inhibits T-cell activation and also binds to ACE257. Ribavirin has an ant-SARS-CoV2 function30. From the bait-host gene PPI, this combination’s complementary drug targets had PPI with 9 virus baits including N, M, orf3a, orf8, nsp7, nsp1, nsp2, nsp13, and nsp14, which might affect the virus replication, assembling, and releasing51.
Hydroxychloroquine and melatonin
Melatonin has been proposed as an adjuvant for COVID-19 treatment58 because Melatonin can limit virus-related diseases with a high profile of safety. This might imply we can reduce the dosage of Hydroxychloroquine that decreases the risk of a long Q-T interval31. This speculation needs further verification.
We also observed conflicts across different validation sources. For example, Aspirin and Albuterol had positive treatment effects in EHRs validation, but there was no positive efficacy in all the four in vitro experiments. Losartan was effective in GSEA but presents negative treatment effects in EHR validation. The reason for this discrepancy might be because each validation source captures different aspects of the drug’s function. The GSEA validation focused on inhibiting or activating the virus-associated host genes. The in vitro efficacy focused on viral entry, replication, or cytopathic effect. The population-based EHRs validation focused on the drugs’ antiviral effect and also clinical symptom relief. For example, Acetaminophen, Azithromycin, and Albuterol are frequently given to hospitalized patients for fever, pneumonia, and shortness of breath, respectively. These drugs might not have direct effects on the virus itself. Concordance in multiple validation sources may strengthen the confidence in the drug’s effectiveness. The drugs with conflicting validation results are still worth investigating.
There are several limitations of this study. Our pipeline might have filtered out some potential drugs prematurely during the initial drug ranking step using the clinical trial drugs. The initial pool of 3635 drug candidates might miss an important set of drugs considering the fast-evolving knowledge of COVID-19 therapeutic agents.
The population-based validation was from retrospective analyses of EHRs, which are inherently incomplete and erroneous compared to randomized experimental data. Our propensity score matching and weighting approach were designed to reduce bias and confounding effects, but unmeasured or hidden confounders may exist in the EHRs data. Important laboratory values measuring the severity of COVID-19, such as White Blood Cell count, d-Dimer, and C-reactive protein, were not well documented in EHRs during the early stage of COVID-19 pandemic. The other limitation is a discrepancy between gene sets from drug-induced gene expression and SARS-CoV-2-infected cell’s gene expression. cMAP provides the expression value for only 12,328 genes while the SARS-CoV-2-infected cell line (GSE153970) contains expression value for 17,899 genes. Consequently, the expression values for some genes in SARS-CoV-2 signature are missing, such as SARS-CoV2-gp10 and SARS-CoV2-gp01, which might cause bias. In spite of differences in cell lines as well as missing expression value of some genes, the results still have some value as a reference for further investigation.
In conclusion, this study proposes an integrative drug repurposing pipeline for the rapid identification of drugs and their combination to treat COVID-19. Our pipelines were developed from extensive SARS-CoV-2 and drug interactions, deep graph neural representation, and ranking model, and validated from genetic profiles, in vitro efficacy, and population-based treatment effects. From a translational perspective, this pipeline can provide a general network pharmacology pipeline for various diseases, which can contribute to fast drug and drug combinations repurposing.
Materials and methods
Building the COVID-19 knowledge graph
To build the COVID-19 knowledge graph, we identified drug-target interactions, pathways, gene/drug-phenotype interactions from CTDbase. We collected the SARS-CoV-2 and host PPIs from a recent systematic PPI experimental study for SARS-CoV-251. The graph had four types of nodes and five types of edges based on the interactions. The four types of nodes include 27 virus baits, 5677 unique host genes (from 322 host preys, 1783 genes on pathways, and 4427 drug targets, Fig. S1), 3635 drugs, and 1285 phenotypes. The five types of edges include 330 virus-host PPIs, 13,423 pairwise genes on the same pathway, 16,972 drug-target pairs, 1401 gene-phenotype pairs, and 935 drug-phenotype pairs. Details on each interaction are as follows:
SARS-CoV-2 and human protein interactions
We collected the SARS-CoV-2 and host interaction data from a recent work that identifies 322 high confidence PPIs between SARS-CoV-2 and the human51. This literature cloned 26 SARS-CoV-2 proteins in human cells and identified the human proteins that were physically associated with the SARS-CoV-2 proteins. We used the SARS-CoV-2 and human protein interaction with MiST > 0.8. In total, the virus-host interaction network consisted of 27 virus baits and 332 SARS-CoV-2-associated prey proteins.
Drug–target interactions
We collected drugs and targets from CTDbase’s COVID-19 curated list, which contains 5065 potential targetable genes for COVID-19 with supporting biological mechanisms or therapeutic evidence. Potential compounds for SARS-CoV-2 were identified if the compounds target the SARS-CoV-2-associated genes. There were 3635 compounds that target 4427 genes. The size of the intersection between host genes interacting with baits and drug targets is 94.
Biological pathways
We incorporated functional pathways related to SARS-CoV-2 infection and drugs of interest. We used the Kyoto Encyclopedia of Genes and Genomes (KEGG59), Reactome (which were curated in CTDbase), and PharmGKB. There were 1,763 unique genes and 13,423 pairs of genes that were associated with the pathways.
Gene/drug–phenotype interactions
We used a curated set of phenotypes from CTDbase, which inferred the phenotypes via drug interaction and/or gene to gene ontology annotation. There were 1,285 phenotypes (i.e., biological process gene ontology) that were associated with 31 potential drugs and/or 18 SARS-CoV-2-associated genes.
Embedding using graph neural network
To derive embedding from the COVID-19 knowledge graph, we utilized deep graph neural embedding with multi-relational data. We used variational graph autoencoders with GraphSAGE messages passing18,20. Due to uncertainty and incompleteness in our knowledge graph (i.e., COVID-19 is an emerging infectious disease and our knowledge on COVID-19 is developing), we chose to use variational autoencoders to account for the uncertainty. The graph autoencoder method is an unsupervised learning framework to encode the nodes into a latent vector (embedding) and reconstruct the given graph structure (i.e., graph adjacency matrix) with the encoded latent vector. The variational version of graph autoencoders is to learn the distribution of the graph to avoid overfitting during the reconstructing the graph adjacency matrix. In the message-passing step, each node’s (entity) embedding is iteratively updated by aggregating the neighbors embedding, in which the aggregation function is a mean of the neighbor’s features, concatenation with current embedding, and a single layer of a neural network on the concatenated one. We set different weight matrices for each of the five types of edges. Since our objective is to use the drug embedding to discover drugs that can functionally target SARS-CoV-2-associated host genes, the model was trained to reconstruct the missing interaction using the node embeddings as an unsupervised manner. We set the embedding size as 128 after several trials. We used PyTorch Geometric for implementation. The model structure was (1 × 400) → Graph convolution to (1 × 256) → RELU → Dropout → Concatenation of multiple edge types → Batch norm → Graph convolution to 1 × 128 (mean) and 1 × 128 (variance).
We further boosted the representativeness of the embedding by transferring DRKG universal embedding to our embedding. The DRKG embedding contains general biological knowledge (e.g., drug embedding was derived from molecular structures, targets, anatomical therapeutic chemical classifications, side effects, pharmacologic classes, and treating diseases)13. By transferring the rich representation of DRKG to the COVID-19 knowledge graph, we can derive embeddings that are more faithful to underlying pharmacokinetics and pharmacodynamics. To this end, we initialized the COVID-19 knowledge graph node embedding with DRKG embedding and fine-tuned the node embedding by updating them via GNN’s message passing and aggregation. (Note S1).
Evaluating the knowledge graph embedding
We internally validated the confidence of our knowledge graph embedding via link prediction to confirm if the node embedding can capture the network topology centered by SARS-CoV-2. We measured an accuracy to predict interactions between the nodes (SARS-CoV-2 baits, genes, drugs, and phenotypes). We randomly selected 10% of the edges for validation.
We also visualize the node embedding using lower-dimensional projection to observe the distribution of high-dimensional node embedding. The t-SNE plot projects a high-dimensional vector into a low-dimension vector while preserving the pairwise similarity between nodes, thus allowing us to examine the high-dimensional node embedding with low-dimension (e.g., 2-dimensions) visualization.
Initial drug ranking
After we derived the drug embedding, we built a ranking model to select the most potent drugs. We hypothesized that, because drugs testing in clinical trials are potentially efficacious in treating COVID-19, a drug that is similar to these trial drugs can have potential efficacy too. This drug ranking was an initial filtering step to select possibly potent drugs out of 3,635 candidates. The drugs under clinical trials were extracted from NIH ClinicalTrials.gov’s interventional trials. 99 trial drugs were matched to the CTDbase’s 3635 drugs. The remaining drugs without matched clinical trials were regarded as having negative efficacy. We designed a customized neural network ranking model based on Bayesian pairwise ranking loss60. The architecture was two fully connected layers (with the size of 128 → 128 → 1) with residual connection, nonlinear activation (ReLU), dropout, batch norm in the middle, and the optimization loss (Bayesian pairwise ranking loss). Baseline ranking models to compare were logistic regression, support vector machine, XGBoost, and Random forest.
We measured the accuracy of the drug ranking model using the area under the receiver operating curve (AUROC) and area under the precision-recall curve (AUPRC) with 50% training and 50% test cross-validation. We purposely set the portion of the training set lower because the clinical trials are not our sole “gold standard” to prioritize drugs. Note that the unsupervised knowledge graph embedding and the supervised drug ranking were independent. We tried to avoid using the supervised label (clinical trials drugs) in the knowledge graph embedding because the drugs being considered in clinical trials do not guarantee the efficacy of the drugs.
Genetic validation
We obtained the gene expression signature of SARS-CoV-2 from SARS-CoV-2 infected human lung cells61, and obtained the drug's gene expression signature profile from the Connectivity Map (cMAP) database (GSE92742 and GSE70138)62. We determined whether the drug’s gene expression signature is negatively correlated with that of SARS-CoV-2 based on the enrichment score (ES)63. The combining ES < 0 and p-value < 0.05 was considered as the threshold to determine that a drug has a complementary expression pattern with COVID-19 infections (Note S3).
Retrospective in vitro drug screening validation
We validated the highly ranked candidate drugs by retrospectively comparing them with efficacious drugs in multiple in vitro drug screening studies. We utilized four drug screening studies targeting viral entry (ACE2 enzymatic activity, Spike-ACE2 protein–protein interaction) and viral replication/infection (cytopathic effect), which are obtained from NCATS OpenData COVID-19 Portal and Riva et al. study7,8. The two viral entry assay studies screened 2,678 compounds in the NCATS Pharmaceutical Collection and 739 compounds in the NCATS Anti-infectives Collection64. In the viral entry assay, a drug was regarded as efficacious if efficacy value was larger than 10 and 0 for ACE2 enzymatic activity and Spike-ACE2 interaction, respectively (the efficacy value was defined as an % inhibition at infinite concentration subtracted by % inhibition at zero concentration by curve fitting). The two cytopathic effects studies use either the NCATS collections or the ReFRAME drug library on the same Vero E6 cell65. In the NCATS cytopathic effect study, a drug was regarded as efficacious if the efficacy value was larger than 10. In the ReFRAME study, a drug was regarded as efficacious if the drug inhibited infection by 40% or more7. We calculated precision and recall between the predicted (top 300 highly-ranked) drugs and the efficacious drugs in each screening result (Fig. 2c). We focused on only those drug candidates that are included in the compound library in the screening study.
Population-based validation
We investigated drugs administered to the COVID-19 patients and estimated treatment effect using counterfactual analysis. We used OptumⓇ de-identified EHR database (2007–2020), which is (non-experimental data, as opposed to randomized clinical trials).
In 140,016 positive COVID-19 patients, there were a total of 34,043 hospitalized COVID-19 patients; we selected 3200 deceased patients during the hospitalization and 15,078 recovered patients with medication history and length of stay > 2 days.
The key to estimate treatment effect is to reduce bias or confounders in EHRs to control the difference of confounding variables between those who received and did not receive treatment. We calculated the average treatment effect on the treated (ATT) by using propensity score matching (PSM) and weighting to build the cohort (Note S2). From the selected hospitalized patients, we built a cohort with 2827 cases (deceased) and 2774 controls (recovered) that follow similar distributions in terms of demographics (race, ethnicity, sex, age) and admission severity (body temperature and SPO2) using PSM. The time period of severity risk factors was from before 2 h of admission and to after 6 h of admission. After we derived the matched cohort, there were a total of 391 medications that were administered in at least 35 patients. We calculated the treatment effect of the 391 medications using the average treatment effect among treated or ATT. For the inverse propensity score weighting, we considered demographics (age, gender, race), admission conditions (body temperature, SPO2), comorbidities (cancer, chronic kidney disease, obesity, a serious heart condition, solid organ transplant, COPD, type II diabetes, and sickle cell disease), and drug history before the treatment of interest. We assumed a drug is effective if ATT > 0 and the p-value is < 0.05. A full list of the drug's ATT coefficient is in Table S3. The Optum de-identified EHR database within this study has been approved by the Committee for the Protection of Human Subjects (UTHSC-H IRB) under protocol HSC-SBMI-13-0549.
Drug combination search
We identified efficacious drug combinations from top-ranked drugs. Our approach is to leverage drug targets and COVID-19 associated host genes. Our working hypothesis was based on the Complementary Exposure pattern that “a drug combination is therapeutically synergistic if the targets of the individual drugs hit the disease module, but target a separate neighborhood”43. We searched the drug combinations within the top 30 drugs. We identified the COVID-19 modules from human protein interactomes that are physically associated with SARS-CoV-2 baits51. The drug’s targets were identified from CTDbase’s COVID-19 curated list. We counted the number of genes in the COVID-19 module that a drug combination hits, where the drug combination’s targets are disjoint.
Data availability
Code is available at https://github.com/yejinjkim/drug-repurposing-graph. Data is available at Supplementary tables. The raw COVID-19 knowledge graph data derived from CTDbase (http://ctdbase.org/).
References
Lu, Q.-B. Reaction cycles of halogen species in the immune defense: Implications for human health and diseases and the pathology and treatment of COVID-19. Cells 9, 1461 (2020).
Office of the Commissioner. FDA Approves First COVID-19 Vaccine. https://www.fda.gov/news-events/press-announcements/fda-approves-first-covid-19-vaccine (2021).
Beigel, J. H. et al. Remdesivir for the treatment of covid-19: Final report. N. Engl. J. Med. 383, 1813–1826 (2020).
Fischer, W. et al. Molnupiravir, an oral antiviral treatment for COVID-19. medRxiv.
Singh, V. K. et al. Emerging prevention and treatment strategies to control COVID-19. Pathogens 9, 501 (2020).
Kumar, Y., Singh, H. & Patel, C. N. In silico prediction of potential inhibitors for the Main protease of SARS-CoV-2 using molecular docking and dynamics simulation based drug-repurposing. J. Infect. Public Health 13, 1210–1233 (2020).
Riva, L. et al. Discovery of SARS-CoV-2 antiviral drugs through large-scale compound repurposing. Nature 586(7827), 113–119 (2020).
Brimacombe, K. R. et al. An OpenData portal to share COVID-19 drug repurposing data in real time. BioRxiv 6, 672 (2020).
Feng, S. et al. Eltrombopag is a potential target for drug intervention in SARS-CoV-2 spike protein. Infect. Genet. Evol. 85, 104419 (2020).
Tu, Y.-F. et al. A review of SARS-CoV-2 and the ongoing clinical trials. Int. J. Mol. Sci. 21, 2657 (2020).
Tang, J. & Aittokallio, T. Network pharmacology strategies toward multi-target anticancer therapies: From computational models to experimental design principles. Curr. Pharm. Des. 20, 23–36 (2014).
Ghaebi, M., Osali, A., Valizadeh, H., Roshangar, L. & Ahmadi, M. Vaccine development and therapeutic design for 2019-nCoV/SARS-CoV-2: Challenges and chances. J. Cell. Physiol. 235(12), 9098–9109 (2020).
Zeng, X. et al. Repurpose open data to discover therapeutics for covid-19 using deep learning. J. Proteome Res. 19, 4624–4636 (2020).
Shah, B., Modi, P. & Sagar, S. R. In silico studies on therapeutic agents for COVID-19: Drug repurposing approach. Life Sci. 252, 117652 (2020).
Qamar, M. T., Alqahtani, S. M., Alamri, M. A. & Chen, L.-L. Structural basis of SARS-CoV-2 3CLpro and anti-COVID-19 drug discovery from medicinal plants. J. Pharm. Anal. 10(4), 313–319 (2020).
Castro, V. M., Ross, R. A., McBride, S. M. J. & Perlis, R. H. Identifying common pharmacotherapies associated with reduced COVID-19 morbidity using electronic health records. MedRxiv
Zhou, Y. et al. Network-based drug repurposing for novel coronavirus 2019-nCoV/SARS-CoV-2. Cell Discov. 6, 1–18 (2020).
Hamilton, W. L., Ying, R. & Leskovec, J. Inductive Representation Learning on Large Graphs (Springer, 2017).
Mohamed, S. K., Nováček, V. & Nounu, A. Discovering protein drug targets using knowledge graph embeddings. Bioinformatics 36, 603–610 (2020).
Kipf, T. N. & Welling, M. Variational Graph Auto-Encoders (Springer, 2016).
Schlichtkrull, M. et al. Modeling Relational Data with Graph Convolutional Networks (Springer, 2017).
Plotly: The front end for ML and data science models. https://plotly.com/.
Ratner, A., De Sa, C., Wu, S., Selsam, D. & Ré, C. Data programming: Creating large training sets quickly. Adv. Neural Inf. Process. Syst. 29, 3567–3575 (2016).
Bleyzac, N., Goutelle, S., Bourguignon, L. & Tod, M. Azithromycin for COVID-19: More than just an antimicrobial?. Clin. Drug Investig. 1, 1–10 (2020).
Xu, H. et al. High expression of ACE2 receptor of 2019-nCoV on the epithelial cells of oral mucosa. Int. J. Oral Sci. 12, 1–5 (2020).
Khurana, S., Gupta, S., Bhalla, H., Nandwani, S. & Gupta, V. Comparison of anti-inflammatory effect of atorvastatin with rosuvastatin in patients of acute coronary syndrome. J. Pharmacol. Pharmacother. 6, 130 (2015).
Solaimanzadeh, I. Nifedipine and amlodipine are associated with improved mortality and decreased risk for intubation and mechanical ventilation in elderly patients hospitalized for COVID-19. Cureus 12, e8069 (2020).
Yang, N. & Shen, H.-M. Targeting the endocytic pathway and autophagy process as a novel therapeutic strategy in COVID-19. Int. J. Biol. Sci. 16, 1724–1731 (2020).
Sharif-Askari, N. S. et al. Cardiovascular medications and regulation of COVID-19 receptors expression. Int. J. Cardiol. Hypertension 6, 100034 (2020).
Khalili, J. S., Zhu, H., Mak, N. S. A., Yan, Y. & Zhu, Y. Novel coronavirus treatment with ribavirin: Groundwork for an evaluation concerning COVID-19. J. Med. Virol. 92, 740–746 (2020).
Mitra, R. L., Greenstein, S. A. & Epstein, L. M. An algorithm for managing QT prolongation in coronavirus disease 2019 (COVID-19) patients treated with either chloroquine or hydroxychloroquine in conjunction with azithromycin: Possible benefits of intravenous lidocaine. Heart Rhythm Case Rep. 6, 244–248 (2020).
Cao, B. et al. A trial of lopinavir-ritonavir in adults hospitalized with severe covid-19. N. Engl. J. Med. 382, 1787–1799 (2020).
Baron, S. A., Devaux, C., Colson, P., Raoult, D. & Rolain, J.-M. Teicoplanin: An alternative drug for the treatment of COVID-19?. Int. J. Antimicrob. Agents 55, 105944 (2020).
Grein, J. et al. Compassionate use of remdesivir for patients with severe covid-19. N. Engl. J. Med. 382, 2327–2336 (2020).
Caly, L., Druce, J. D., Catton, M. G., Jans, D. A. & Wagstaff, K. M. The FDA-approved drug ivermectin inhibits the replication of SARS-CoV-2 in vitro. Antiviral Res. 178, 104787 (2020).
Gimeno, A. et al. Prediction of novel inhibitors of the main protease (M-pro) of SARS-CoV-2 through consensus docking and drug reposition. Int. J. Mol. Sci. 21, 3793 (2020).
Wu, C. et al. Analysis of therapeutic targets for SARS-CoV-2 and discovery of potential drugs by computational methods. Acta Pharm. Sin. B 10, 766–788 (2020).
Weston, S., Haupt, R., Logue, J., Matthews, K. & Frieman, M. B. FDA approved drugs with broad anti-coronaviral activity inhibit SARS-CoV-2 in vitro. (2020).
Al-Khikani, F. & Hameed, R. COVID-19 treatment: Possible role of itraconazole as new therapeutic option. Int. J. Health Allied Sci. 9, 101–101 (2020).
Mauvais-Jarvis, F., Klein, S. L. & Levin, E. R. Estradiol, progesterone, immunomodulation and COVID-19 outcomes. Endocrinology 161, 127 (2020).
Del Amo, J. et al. Incidence and severity of COVID-19 in HIV-positive persons receiving antiretroviral therapy: A cohort study. Ann. Intern. Med. 173(7), 536–541 (2020).
Kim, Y. et al. Anti-cancer drug synergy prediction in understudied tissues using transfer learning. J. Am. Med. Inform. Assoc. 28(1), 42–51 (2020).
Cheng, F., Kovács, I. A. & Barabási, A.-L. Network-based prediction of drug combinations. Nat. Commun. 10, 1197 (2019).
Ono, K. Cytoscape. https://cytoscape.org/.
Kawasaki, T. & Kawai, T. Toll-like receptor signaling pathways. Front. Immunol. 5, 461 (2014).
Arshad, S. et al. Treatment with hydroxychloroquine, azithromycin, and combination in patients hospitalized with COVID-19. Int. J. Infect. Dis. 97, 396–403 (2020).
A Review of the SARS-CoV-2 (COVID-19) Genome and Proteome. https://www.genetex.com/MarketingMaterial/Index/SARS-CoV-2_Genome_and_Proteome.
Warner, T. D., Nylander, S. & Whatling, C. Anti-platelet therapy: Cyclo-oxygenase inhibition and the use of aspirin with particular regard to dual anti-platelet therapy. Br. J. Clin. Pharmacol. 72, 619 (2011).
Xu, P., Zhou, Q. & Xu, J. Mechanism of thrombocytopenia in COVID-19 patients. Ann. Hematol. 99, 1205 (2020).
Wang, G. et al. C-reactive protein level may predict the risk of covid-19 aggravation. Open Forum Infect. Dis. 7, 153 (2020).
Gordon, D. E. et al. A SARS-CoV-2 protein interaction map reveals targets for drug repurposing. Nature 583, 459–468 (2020).
Zhang, L. et al. Calcium channel blocker amlodipine besylate is associated with reduced case fatality rate of COVID-19 patients with hypertension. Cell Discov. 6(1), 1–12 (2020).
Khurana, I. et al. Can bilirubin nanomedicine become a hope for the management of COVID-19?. Med. Hypotheses 149, 110534 (2021).
Allawadhi, P. et al. Decorin as a possible strategy for the amelioration of COVID-19. Med. Hypotheses 152, 110612 (2021).
Takami, A. Possible role of low-dose etoposide therapy for hemophagocytic lymphohistiocytosis by COVID-19. Int. J. Hematol. 112, 122–124 (2020).
Thong, Y. H., Ferrante, A., Rowan-Kelly, B. & O’Keefe, D. E. Effect of mefloquine on the immune response in mice. Trans. R. Soc. Trop. Med. Hyg. 73, 388–390 (1979).
Sonmez, A. et al. Effects of losartan treatment on T-cell activities and plasma leptin concentrations in primary hypertension. J. Renin Angiotensin Aldosterone Syst. 2, 112–116 (2001).
Salles, C. Correspondence COVID-19: Melatonin as a potential adjuvant treatment. Life Sci. 253, 117716 (2020).
Kanehisa, M., Furumichi, M., Sato, Y., Ishiguro-Watanabe, M. & Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 49, D545–D551 (2021).
Rendle, S., Freudenthaler, C., Gantner, Z. & Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. (2012).
Vanderheiden, A. et al. Type I and type III IFN restrict SARS-CoV-2 infection of human airway epithelial cultures. J. Virol. 382, 727 (2020).
Subramanian, A. et al. A next generation connectivity map: L1000 Platform and the first 1,000,000 profiles. Cell 171, 1437-1452.e17 (2017).
Lamb, J. The connectivity map: Using gene-expression signatures to connect small molecules, genes, and disease. Science 313, 1929–1935 (2006).
Huang, R. et al. The NCGC pharmaceutical collection: A comprehensive resource of clinically approved drugs enabling repurposing and chemical genomics. Sci. Transl. Med. 3, 8016 (2011).
Janes, J. et al. The ReFRAME library as a comprehensive drug repurposing library and its application to the treatment of cryptosporidiosis. Proc. Natl. Acad. Sci. USA. 115, 10750–10755 (2018).
Acknowledgements
We thank Lu Chen and Hall Matthew from NCATS for in vitro efficacy experiments.
Funding
Y. K. was supported in part by CPRIT RR180012, R01AG066749, and R01AG066749-01S1. K. H. was supported by CPRIT RR180012. Y. W. and J. T. were supported by ERC starting Grant No. 716063 and Academy of Finland funding No. 3176880. Z. Z. is partially supported by NIH grant R01LM012806 and CPRIT grant CPRIT RP180734. X. J. is CPRIT Scholar in Cancer Research (RR180012), and he was supported in part by Christopher Sarofim Family Professorship, UT Stars award, UTHealth startup, the National Institute of Health (NIH) under Award Number R01AG066749 and R01AG066749-01S1.
Author information
Authors and Affiliations
Contributions
X.J., J.T. and Z.Z. provided motivation for this study; X.J., K.H., and Y.W. collected necessary data; Y.K. built graph representation and ranking models; X.J. and L.C. performed population-based validation; Y.W. and K.H. performed genetic validation; K.H. and J.T. derived drug combinations; K.H. prepared plots; Y.K., K.H., Y.W., J.T., Z.Z., S.S., and X.J. wrote manuscript; and K.H. and S.S. provided clinical interpretation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hsieh, K., Wang, Y., Chen, L. et al. Drug repurposing for COVID-19 using graph neural network and harmonizing multiple evidence. Sci Rep 11, 23179 (2021). https://doi.org/10.1038/s41598-021-02353-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-02353-5
This article is cited by
-
Computational insight of repurpose drug for treatment of COVID-19: a CDFT approach
Theoretical Chemistry Accounts (2024)
-
Molecular-evaluated and explainable drug repurposing for COVID-19 using ensemble knowledge graph embedding
Scientific Reports (2023)
-
Computational drug repurposing based on electronic health records: a scoping review
npj Digital Medicine (2022)
-
A computational study of potential therapeutics for COVID-19 invoking conceptual density functional theory
Structural Chemistry (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
