
Abstract
This study looked at novel data sources for cardiovascular risk prediction including detailed lifestyle questionnaire and continuous blood pressure monitoring, using ensemble machine learning algorithms (MLAs). The reference conventional risk score compared against was the Framingham Risk Score (FRS). The outcome variables were low or high risk based on calcium score 0 or calcium score 100 and above. Ensemble MLAs were built based on naive bayes, random forest and support vector classifier for low risk and generalized linear regression, support vector regressor and stochastic gradient descent regressor for high risk categories. MLAs were trained on 600 Southeast Asians aged 21 to 69 years free of cardiovascular disease. All MLAs outperformed the FRS for low and high-risk categories. MLA based on lifestyle questionnaire only achieved AUC of 0.715 (95% CI 0.681, 0.750) and 0.710 (95% CI 0.653, 0.766) for low and high risk respectively. Combining all groups of risk factors (lifestyle survey questionnaires, clinical blood tests, 24-h ambulatory blood pressure and heart rate monitoring) along with feature selection, prediction of low and high CVD risk groups were further enhanced to 0.791 (95% CI 0.759, 0.822) and 0.790 (95% CI 0.745, 0.836). Besides conventional predictors, self-reported physical activity, average daily heart rate, awake blood pressure variability and percentage time in diastolic hypertension were important contributors to CVD risk classification.
Similar content being viewed by others


Introduction
Prevention of cardiovascular disease is based on the tenet that atherosclerotic disease occurs over time; risk factors and lifestyle are contributory, and appropriate modification can delay the onset of cardiovascular events. Previously established cardiovascular risk assessment models such as Framingham Risk Score (FRS)1, Systematic Coronary Risk Evaluation (SCORE)2 and QRISK2 score3 predict future risk based on well-established medical risk factors and pay little attention to lifestyle factors.
Recent studies highlighted the potential of lifestyle data in predicting cardiovascular risk4. The INTERHEART study found that nine risk factors including smoking, history of hypertension or diabetes, waist/hip ratio, dietary patterns, physical activity, consumption of alcohol, blood apolipoproteins (Apo), and psychosocial factors, accounted for 90% of the population attributable risk for myocardial infarction in men and 94% in women. These suggest room to improve cardiovascular risk assessment by incorporating new factors such as physical activity status, lifestyle and dietary habits5,6 alongside traditional risk predictors.
Prior studies have shown demonstrated increased cardiovascular risk from elevated blood pressure7,8,9; the PAMELA study found that combining office, rest and ambulatory blood pressure help predict cardiovascular mortality up to an area under curve of 0.81. Risk modelling have also been done of dietary and lifestyle behaviour, although the frequency of the studies is lower due to the need to administer detailed, time consuming food frequency questionnaires10. However due to the diverse data sources, and data types including time series, an integrated assessment tool combining lifestyle, diet, ambulatory physiological parameters, and clinical risk markers have not been performed to our knowledge.
Cardiovascular risk scores derived from traditional biostatistical methods such as logistic regression and Cox proportional hazard models11,12,13 provide parsimonious interpretation. However, their strict assumptions such as homoscedasticity, distribution normality and relationship linearity tend to oversimplify complex relationships and limit applications14. Machine learning algorithms (MLA) in studies15,16,17 were able to overcome these statistical drawbacks and improve discriminatory performance over traditional models. More recently, ensemble modelling techniques have also gained popularity such as in prediction of heart disease18,19, diabetes and hypertension20 cancer diagnosis and classification21,22. An ensemble model combines the different MLAs into one predictive model. Compared to a single model, an ensemble model is more robust and offers higher goodness-of-fit and better prediction accuracy23.
The aim of this paper is to investigate the additive value of four groups of risk factors, based on ease of information availability and regular clinical workflow, (lifestyle survey questionnaires, clinical blood tests, 24 h ambulatory blood pressure and heart rate monitoring) using ensemble MLA, in cardiovascular risk prediction. Due to limitations of the traditional biostatistical models, we used an ensemble MLA technique to learn the complex and non-linear interactions amongst the different groups of risk factors. To date, the application of ensemble MLA on lifestyle factors and clinical variables for individualised CVD risk assessment remains underexplored.
Methods
Data source and study population
Data used in this study was drawn from a SingHEART prospective longitudinal cohort study (ClinicalTrials.gov Identifier: NCT02791152). The study is a multi-ethnic population-based study conducted on healthy Asians, aged 21–69 years old without known diabetes mellitus or prior cardiovascular disease (Ischemic heart disease, stroke, peripheral vascular disease). The study complied with the Declaration of Helsinki and written informed consent were given by participants. The study was approved by the SingHealth Centralized Institutional Review Board.
We included 600 volunteers, aged of 30 years with valid calcium score, into the main analysis of this study. Two hundred volunteers under the age of 30 years, who did not have a calcium score were excluded, as the calcium score was the main outcome of our analysis.
Subset analysis for activity tracker data was performed on 430 out of the 600 volunteers who had adequate data. Although subjects recruited were issued an activity tracker to be worn over a period of five days with first and last days of the study being partial days, there was inconsistent wearing of the activity. Discounting the partial days, each subject would yield an activity log for three complete tracking days (or equivalent to days with > 20 valid hours of steps and sleep data)24,25. For data consistency and quality, subjects with improper activity tracker usage i.e. activity reading log less than five days and/or sleep reading log less than three days were censored.
Markers of CVD risk and outcome
Coronary artery calcium (CAC) scoring was used as the modelling outcome. The coronary calcium is a specific marker of coronary atherosclerosis, a precursor for coronary artery disease26; it also reflects arterial age under the influence of underlying comorbidities and lifestyle. The CAC score was also regarded as the best marker for risk prediction of cardiovascular events27,28.
This study stratified subjects into two classes of CVD risk. Low risk if their coronary artery calcium score were 0, and high risk if calcium score were 100 and above. Subjects who did not fall into these 2 categories were considered intermediate risk.
The aim of this study is to look at how accurate the machine learning algorithm is in handling different data types, in the task of predicting high risk and low risk patients, based on calcium score.
Data variables used for MLA: lifestyle survey questionnaires, clinical blood tests, ambulatory blood pressure and activity tracking data
Table 1 summarizes the data from SingHEART that was used in this study.
Data variables were categorized into four groups; lifestyle survey questionnaires, blood test data, 24-h ambulatory blood pressure, and activity tracking data by commercially available Fitbit Charge HR29.
Data pre-processing, transformation and imputation were performed on the raw data. Variables selected were based on their a priori knowledge from previous publications on cardiovascular risk assessment1,2,3, and physician expert advice. In total, there were 30, 17, 12 and 16 unique variables in the respective groups: survey questionnaire, 24 h blood pressure and heart rate monitoring, blood tests and Fitbit data.
Framingham risk score (FRS) as the comparator
The Framingham 10-year risk score was computed using seven traditional risk factors: gender, age, single timepoint systolic blood pressure, Total Cholesterol (TC), High Density Lipoprotein (HDL), smoking status and presence of diabetes. A Framingham risk score of < 10% is consider low risk, while ≥ 20% is considered high risk30.
Modelling pipeline
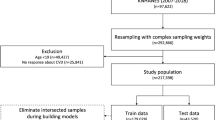
Figure 1 shows the methodological framework of the present study. Exploratory analysis showed that ensemble MLA classifiers were superior at discriminating low risk individuals while ensemble MLA regressors performed better identifying individuals with high CVD risk. To leverage on the merits of both the classifiers and regressors MLA, we used both approaches for our model.

Modelling flow chart using ensemble MLA for cardiovascular risk prediction.
The ensemble classifiers produce a binary prediction outcome; low or non-low risk. The ensemble regressors makes a numerical prediction on the calcium score for individuals classified as non-low risk, and stratify into three bins of low, high, and intermediate risk. The predicted numerical values may range from negative to positive number. Negative predicted values were first converted to zero and subsequently the continuous predictions were converted to discrete bins using unique value percentile discretization ensuring records with the same numerical prediction are assigned the same risk category. Finally, the prediction outcome resides in a decision node build on a rule-based logic. The decision node assigns an outcome of low risk if classifiers predict an individual to be low in CVD risk, high risk if classifier predicts non-low risk and regressor predicts high risk. Patients with incongruent classifiers and regressor outcomes are considered unclassified.
The ensemble models in both classification and regression phase each fit three base learners (naive bayes (NB), random forest (RF) and support vector classifier (SVC) for classification prediction, and generalized linear regression (GLM), support vector regressor (SVR) and stochastic gradient descent (SGD) for regression prediction). These base learners were chosen based on preliminary analysis, where these models showed efficiency in handling missing values and outliers.
The ensemble model then uses majority vote to determine the class label in classification phase. For the regression phase, the ensemble model averages the normalized predictions from the base regressor models to form a numerical outcome.
All models were trained on a stratified five-fold cross-validation. As SingHEART data had an imbalanced CVD risk distribution of risk based on the calcium score (low risk 63.4%, high risk 8.3%, intermediate risk 18.7%) we oversampled the training set for the minority class labels to allow model to better learn features from the under-represented classes31. The data were first partitioned into five mutually exclusive subsets, with each subset sharing the same proportion of class label as original dataset. At each iteration, the MLAs trained on four parts (80%) and validated on the fifth, the holdout set (20%). The process repeats five times, with five different but overlapping training sets. The resulting metrics from each fold were averaged to produce a single estimate.
To simulate access to the different variable groups as per clinical workflow and ease of information availability, we assessed the performance of individual variable group, and in combination as per the following:
Model 1: Survey Questionnaire.
Model 2: 24 h ambulatory blood pressure and heart rate.
Model 3: Clinical blood results.
Model 4: Model 1 + Model 2.
Model 5: Model 1 + Model 3.
Model 6: Model 1 to Model 3.
Model 6*: Model 1 to Model 3 with feature selection.
Model 7: Physical activity and sleep trackers (exploratory subset analysis).
Variables in model 6* were reduced using SVC recursive feature elimination with cross-validation (SVC-RFECV) method to automatically select the best set of predictors that yield the highest area under Receiver Operating Characteristic curves (AUC). Model 1–6 were trained using 600 subjects.
We also performed exploratory analysis using MLA on the Fitbit Charge HR data (Model 7). Model 7 was trained on a subset of 430 subjects constrained by availability of valid activity tracking data.
Evaluation methodology and metrics
Since no single metric can objectively evaluate the cardiovascular risk prediction, we evaluate the performance of our models at CVD risk class level using a panel of metrics; sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), F1-score and Area under Receiver Operating Characteristic curves (AUC). Overall discriminative ability of the model was described by the area under received operating characteristic curve (ROC). All AUC metrics were accompanied by 95% confidence interval (CI) and standard deviation (SD).
To better understand the relative importance of different risk factors, we conduct a post-hoc approach to rank the variables by their contribution to CVD risk prediction. Feature importance were obtained from the SVC algorithm where the relative importance was determined by the absolute size of the coefficients in relation to others. All statistical analyses were conducted on Python version 3.7 environment and all MLAs and evaluation metrics were constructed using Scikit-learn libraries.
Results
Baseline characteristics
The SingHEART data consist of 800 anonymized individuals. After excluding cases no coronary calcium scan and other missing information, 600 subjects were used for this analysis. Tables 2, 3, 4, 5 presents the demographics, lifestyle survey questionnaires, clinical blood test and activity tracking data characteristics stratified by CVD risk class. The p-values displayed are obtained by comparing low and high risk categories. Continuous variables are presented in mean values with ± standard deviations while variables are categorical responses are expressed in count and percentage.
The cohort had a mean age of 49.6 years (range 29 to 69 years) and 46% were males. All the factors in the Framingham Risk score were significantly different between the low and high-risk classes on univariate analysis.
In novel parameters such as 24 h ambulatory blood pressure and heart rate, higher measures and derivatives of blood pressure measurement were congruously associated with increased risk (p-value < 0.001). Patients with lower risk had a lower mean average heart rate.
Model performance
AUC for 4 individual variable groups of survey questionnaires, clinical blood tests, 24 h blood pressure and heart rate monitoring, and activity tracker all performed better than the conventional FRS for both low risk and high risk patients (p-value < 0.001). Of all the individual variable groups, survey questionnaires achieved the highest AUC score for both low risk (AUC 0.715 95% CI 0.681–0.750) and high risk (AUC 0.710 95% CI 0.653–0.766). Adding clinical blood tests to survey questionnaire did not improve AUC for both the low risk (p-value = 0.441) and high risk (p-value = 0.715) categories. Adding 24 h blood pressure and heart rate monitoring significantly improved the overall performance compared to the Model 1 using survey questionnaire only, with significant p-values of 0.01 for low risk and 0.005 for high risk groups.
Table 6 demonstrated the cross validated model performance, by evaluating sensitivity, specificity, positive predictive value, negative predictive value, F1 and AUC. FRS had high sensitivity (91.4%) and low specificity (32.9%) in detecting low risk individuals, and low sensitivity (3.7%) and high specificity (99.3%) in detecting high risk individuals. The MLA models achieved a better balance between sensitivity and specificity.
The continuous net reclassification of the lifestyle questionnaire survey variables over FRS in our population were 18% for low cardiovascular risk prediction and 39% for high cardiovascular risk prediction. For the combined Model 6*, the continuous net reclassification over FRS were 25% and 119% for low and high risk categories respectively. Figure 2 shows the receiver operating curves comparing the various models in the low and high cardiovascular risk groups based on their CAC.

ROC curves for low risk group (left) and high risk group (right). Colours and line style represent the prediction performance for different models. Prediction performance for both low and high risk groups were significantly better in model 5* compared to FRS.
Conventional risk factor variables such as age, blood pressure readings, gender and family history of ischemic heart disease were the top ranking contributors to risk prediction in Model 1 (lifestyle survey). Other less conventional but important contributors include self-assessed physical activity and sleep hours.
For Model 2, 24-h blood pressure and heart rate monitoring, percentage time of blood pressure > 120/80 mmHg appeared to be most important compared to other blood pressure readings. Average real variability of blood pressure during wake period and percentage time of nocturnal diastolic hypertension ≥ 70 mmHg were also featured by the model.
In Model 3, clinical blood test variables, conventional risk factor variables of glucose, AST, haemoglobin, albumin and cholesterol readings topped the feature importance ranking.
In the exploratory analysis concerning activity tracking data, minutes in “fairly active” and “very active”, and sleep-related activity log particularly, minutes of REM and minutes of light sleep data were more important features than average daily steps, distance and floors.
Summing all the factors, age, medication for blood pressure and dyslipidemia, albumin, glucose, wake period diastolic hypertension, LDL cholesterol, self-reported physical activity were the top predictors across multiple models (see Fig. 3).

The top 15 features of MLA models showing the relative importance of the different variables in CVD risk prediction. Age, glucose, cholesterol LDL, wake period blood pressure variability, medication for BP and dyslipidemia, triglycerides and albumin reading were some common predictors across the different versions.
Discussion
This study looked at four groups of variables (survey questionnaires, clinical blood tests, 24 h ambulatory blood pressure and heart rate monitoring and activity trackers) and their association with CAC score, for cardiovascular risk classification. We designed our modelling approach by first examining the discriminatory performance of variables in readily accessible, self-reported survey questionnaire group, which did not require equipment or blood test. The incremental contribution to the models’ performance were examined by sequentially adding other groups of variables, simulating availability of information as per clinical workflow. This was compared to the traditional FRS framework.
Previous well-established risk scores such as FRS1, SCORE2 and QRISK2 score3 were mostly derived using traditional risk factors like age, total cholesterol, HDL, systolic BP, smoking and diabetes, excluding physical activity, lifestyle and dietary habits. In our study, we found the risk estimation derived from the FRS framework to be suboptimal with an AUC of 0.622 and 0.515 when applied on the Asian population of low and high risk profiles respectively. The moderate performance of FRS in our cohort corresponds prior published literature in primary care clinics in Asia32, although some other larger cohort studies suggest higher areas under the curve of up to 0.76833,34. While traditional risk factors remain robust, we hypothesize that non-traditional, personalized risk factors such as dietary intake, physical activity and ambulatory blood pressure can contribute to individual cardiovascular risk assessment. Recent studies such as CARDIA35 has demonstrated such potential, and we explored these novel variables using machine learning algorithms. Beyond enhancing individualised cardiovascular risk prediction, this allows users to identify modifiable behavioural factors that can improve risk profiles.
In this healthy Asian ethic population, we found that variables from survey questionnaire achieved an AUC of 0.715 and 0.710 for individuals with low and high CVD risk respectively. Interestingly, we observed that the addition of clinical blood tests on top of survey questionnaire risk factors did not significantly enhance ensemble MLA’s ability in classifying low and high cardiovascular risk, with non-significant p-values when the combined model (Model 5) was compared to the survey questionnaire model (Model 1). This suggests that potential of designing MLA-based survey questionnaire that can be easily implemented, for risk stratification. The survey questionnaire, without need for blood tests is less cumbersome and can be implemented as a population-wide survey, to risk stratify patients. This finding complements the currently available health risk appraisals36 which highlights health risk, but does not diagnose or risk stratify patients, which our current model can do. Our model can potentially vary risk outputs based on changes in lifestyle behaviours included within the questionnaires; this gives patients an actionable plan beyond medications, to reduce their cardiovascular risk.
The ideal cut-off for hypertension has been a constant debate37,38,39 and our study revealed interesting predictors which requires further study. While in-clinic and self-measured blood pressure are single timepoint measurements, they do not reflect the actual variability and time-in-range for blood pressure when a person is performing their activities. There has been varying results in the correlation of blood pressure with cardiovascular events and end-organ outcomes40,41,42. However there has been supporting studies, suggesting that the blood pressure of 120/80 will be optimal in preventing adverse cardiovascular events, especially strokes42,43,44. Our MLA models have identified that a greater percentage time in blood pressure < 120/80 is associated with a better cardiovascular profile. This brings about a new concept of time in range, which is an increasingly important measure in diabetology45, Our study suggests that time-in-range may be extrapolated to hypertension. Additionally, our study also indicated the importance of the daytime variability of blood pressure, which is increasingly recognised to be a marker of cardiovascular risk to be also an important contributor. This concept is supported by recent studies demonstrating association of increased variability with cardiovascular risk46,47,48. Although current blood pressure monitoring devices are single time-point, future wearables may be able to provide the time-in-range readouts and diurnal variability, which were important components associated with atherosclerosis in our study.
The physical activity data in our subgroup also revealed interesting findings in that active minutes were more important than total step count in predicting coronary atherosclerosis. This suggests that achieving the required metabolic equivalents and target heart rate is more important than distance travelled or steps taken in line with physical activity guideline of achieving 150 min of moderate physical exercise per week49.
A practical application of our findings would be in terms of statin prescription, by being able to modestly discern low risk and non-low risk, defined as calcium score 0 and calcium more than 0. The American College of Cardiology suggests patients with zero calcium score on coronary arteries (very low risk patients) can defer of statin therapy in the absence of elevated cardiac risk of ≥ 20% in 10 years50. In this study, we found our ensemble MLA performed better than the Framingham risk score in identifying low risk individuals (p-value < 0.001).
While there have been numerous studies on CVD risk prediction, studies involving the application of ensemble MLA on contemporary risk factors such as lifestyle and ambulatory physiological data on Asian population remains understudied. In51, a study modelled on survey-based responses suggest promising findings in detection of cardiovascular risk patients. Our work extends previous findings by examining the predictive value of the different groups of risk factors and their combined effect to classify CVD risk among healthy asymptomatic individuals in Asian population. Another key contribution of our study is identifying novel risk factors which contributes to CVD risk classification. Our approach prioritizes on easily obtainable variables where inputs to the risk prediction models is not restricted to laboratory or other advanced cardiac imaging test for classification of CVD risk; our models are versatile in that while providing more information helps refine risk prediction, simple health behaviour and lifestyle inputs can already provide a risk prediction. From a population health perspective, this helps create patient self-awareness of health status, and motivate higher risk patients to seek therapy early, thereby lowering health care expenditure in long run. This work therefore present opportunities for use of self-assessed questionnaire data as a preliminary low-cost option to screen healthy individuals for CVD risk. Finally, we also demonstrated the suitability of machine learned models when on applied on dataset with numerous potential predictors. The use of an ensemble modelling technique to synthesize the outcome of multiple base learners can increase model’s robustness and prevent overfitting.
Limitation and future work
In our subanalysis of physical activity Fitbit charge HR parameters, we found that data from such devices were unable to risk stratify patients with high confidence. We attribute the inconclusive performance due to relatively small sample size of patients with adequate Fitbit data, especially for patients in the high risk categories. Patients with high CVD risk accounts for 9.2% (55 out of 600) of the dataset in comparison to 70.2% (421) patients in low risk. Congruent with prior studies, we found associations between activity tracker determined physical activities, sleeping hours and sleep quality with cardiovascular health52, but we will need a larger sample size study before such parameters can be reliably incorporated into a risk model.
Our study is limited by a smaller sample size of patient with high CVD risk defined as calcium score ≥ 100. Individuals with high CVD risk accounts for 20.1% (124) of the dataset in comparison to 70.2% (421) individuals in low risk. We addressed the class-imbalance problem with synthetic minority oversampling technique (SMOTE) by generating synthetic samples of the minority class. SMOTE will not only mitigates the problem of overfitting caused by random oversampling, it will also create more instances of the minority class for MLA to learn53. We also performed only internal validation. This model is built on data from an Asian population, applicability to other populations will require further calibration. Additionally, we only assessed the performance of the model in high and low risk patients; this is due to the limited sample size and to prevent overfitting of the data. We will present this data after the completion of our prospective trial consisting of at least 2000 patients.
As an extension to current work, longitudinal follow-up information will be added enriched the dataset by examining the continuity of each variable across different time points. A prospective trial evaluating this model is planned to provide a larger sample size for learning and model evaluation. Deep learning frameworks capable of capturing the complex interactions while preserving the order and temporal elements of the multiple readings can be explored in place of MLAs for more accurate CVD risk classification.
Data availability
The datasets that support the findings of this study are not publicly available due to personal data protection and ethical reasons. The data can be made available and the corresponding authors may be contacted for access to data for an IRB approved collaboration.
Abbreviations
- ALT:
-
Alanine aminotransferase
- AST:
-
Aspartate transaminase
- AUC:
-
Area under receiver operating characteristics
- ARV:
-
Average real variability
- BP:
-
Blood pressure
- CAC:
-
Coronary artery calcium
- CVD:
-
Cardiovascular disease
- FPR:
-
False positive rates
- FRS:
-
Framingham risk score
- HDL:
-
High-density lipoprotein cholesterol
- LDL:
-
Low-density lipoprotein cholesterol
- MLA:
-
Machine learning algorithms
- NHCS:
-
National Heart Centre Singapore
- NPV:
-
Negative predictive values
- PPV:
-
Positive predictive values
- ROC:
-
Receiver operating characteristics
- SMOTE:
-
Synthetic minority oversampling technique
- TPR:
-
True positive rates
References
Massaro, J.M., et al., General cardiovascular risk profile for use in primary care the Framingham Heart Study. 2008.
Conroy, R. M. et al. Estimation of ten-year risk of fatal cardiovascular disease in Europe: The SCORE project. Eur. Heart J. 24(11), 987–1003 (2003).
Hippisley-Cox, J. et al. Predicting cardiovascular risk in England and Wales: Prospective derivation and validation of QRISK2. BMJ 336(7659), 1475–1482 (2008).
Weng, S. F. et al. Can machine-learning improve cardiovascular risk prediction using routine clinical data?. PLoS ONE 12(4), e0174944 (2017).
Cooney, M. T., Dudina, A. L. & Graham, I. M. Value and limitations of existing scores for the assessment of cardiovascular risk: A review for clinicians. J. Am. Coll. Cardiol. 54(14), 1209–1227 (2009).
Hemann, B. A., Bimson, W. F. & Taylor, A. J. The framingham risk score: An appraisal of its benefits and limitations. Am. Heart Hosp. J. 5(2), 91–96 (2007).
Yoon, S. S. et al. Trends in blood pressure among adults with hypertension: United States, 2003 to 2012. Hypertension 65(1), 54–61 (2015).
Sussman, J., Vijan, S. & Hayward, R. Using benefit-based tailored treatment to improve the use of antihypertensive medications. Circulation 128(21), 2309–2317 (2013).
Mancia, G. et al. Adding home and/or ambulatory blood pressure to office blood pressure for cardiovascular risk prediction. Hypertension 77(2), 640–649 (2021).
Chiuve, S. E. et al. Lifestyle-based prediction model for the prevention of CVD: The Healthy Heart Score. J. Am. Heart Assoc. 3(6), e000954 (2014).
Khanna, D. et al. Comparative study of classification techniques (SVM, logistic regression and neural networks) to predict the prevalence of heart disease. Int. J. Mach. Learn. Comput. 5(5), 414 (2015).
Jia, X., et al. A Cox-based Model for Predicting the Risk of Cardiovascular Disease. in CONF-IRM. 2019.
Li, Y. et al. Examining the impact of data quality and completeness of electronic health records on predictions of patients’ risks of cardiovascular disease. Int. J. Med. Inform. 133, 104033 (2020).
Benediktsson, J.A., P.H. Swain, and O.K. Ersoy, Neural network approaches versus statistical methods in classification of multisource remote sensing data. 1990.
Teoh, D. Towards stroke prediction using electronic health records. BMC Med. Inform. Decis. Mak. 18(1), 1–11 (2018).
Fouayzi, H., A.S. Ash, and A.K. Rosen, A cardiovascular disease risk prediction algorithm for use with the Medicare current beneficiary survey. Health Services Research, 2020.
Almustafa, K. M. Prediction of heart disease and classifiers’ sensitivity analysis. BMC Bioinf. 21(1), 278 (2020).
Gao, X.-Y., et al., Improving the Accuracy for Analyzing Heart Diseases Prediction Based on the Ensemble Method. Complexity, 2021. 2021.
Mienye, I. D., Sun, Y. & Wang, Z. An improved ensemble learning approach for the prediction of heart disease risk. Inform. Med. Unlocked 20, 100402 (2020).
Fitriyani, N. L. et al. Development of disease prediction model based on ensemble learning approach for diabetes and hypertension. IEEE Access 7, 144777–144789 (2019).
Lu, J. et al. Machine learning for assisting cervical cancer diagnosis: An ensemble approach. Futur. Gener. Comput. Syst. 106, 199–205 (2020).
Jabbar, M. A. Breast cancer data classification using ensemble machine learning. Eng. Appl. Sci. Res. 48(1), 65–72 (2021).
Dinh, A. et al. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inform. Decis. Mak. 19(1), 211 (2019).
Yap, J. et al. Harnessing technology and molecular analysis to understand the development of cardiovascular diseases in Asia: A prospective cohort study (SingHEART). BMC Cardiovasc. Disord. 19(1), 259 (2019).
Lim, W. K. et al. Beyond fitness tracking: The use of consumer-grade wearable data from normal volunteers in cardiovascular and lipidomics research. PLoS Biol. 16(2), e2004285 (2018).
Agatston, A. S. et al. Quantification of coronary artery calcium using ultrafast computed tomography. J. Am. Coll. Cardiol. 15(4), 827–832 (1990).
Folsom, A. R. et al. Coronary artery calcification compared with carotid intima-media thickness in the prediction of cardiovascular disease incidence: The Multi-Ethnic Study of Atherosclerosis (MESA). Arch. Intern. Med. 168(12), 1333–1339 (2008).
Yeboah, J. et al. Comparison of novel risk markers for improvement in cardiovascular risk assessment in intermediate-risk individuals. JAMA 308(8), 788–795 (2012).
Gorny, A. W. et al. Fitbit charge HR wireless heart rate monitor: Validation study conducted under free-living conditions. JMIR Mhealth Uhealth 5(10), e157 (2017).
D’agostino, R. B. et al. General cardiovascular risk profile for use in primary care. Circulation 117(6), 743–753 (2008).
Maxwell, A. et al. Deep learning architectures for multi-label classification of intelligent health risk prediction. BMC Bioinformatics 18(Suppl 14), 523 (2017).
Chia, Y. C. et al. Validation of the Framingham general cardiovascular risk score in a multiethnic Asian population: A retrospective cohort study. BMJ Open 5, 5 (2015).
Barzi, F. et al. Cardiovascular risk prediction tools for populations in Asia. J. Epidemiol. Community Health 61(2), 115–121 (2007).
Selvarajah, S. et al. Comparison of the framingham risk score, SCORE and WHO/ISH cardiovascular risk prediction models in an Asian population. Int. J. Cardiol. 176(1), 211–218 (2014).
Gooding, H. C. et al. Application of a lifestyle-based tool to estimate premature cardiovascular disease events in young adults: The coronary artery risk development in young adults (CARDIA) Study. JAMA Intern. Med. 177(9), 1354–1360 (2017).
Gazmararian, J. A. et al. Comparing the predictive accuracy of health risk appraisal: The Centers for Disease Control versus Carter Center program. Am. J. Public Health 81(10), 1296–1301 (1991).
Bolli, P. et al. High normal blood pressure and prehypertension: The debate continues. Can. J. Cardiol. 23(7), 581–583 (2007).
Yousefifard, M. & Hosseini, M. Should the cutoff for hypertension in older adults be different from younger adults?. Lancet 392(10163), 2438–2439 (2018).
Goel, H., H. Tayel, and S.K. Nadar, Aiming higher in hopes to achieve lower: the European Society of Cardiology/European Society of Hypertension versus the American College of Cardiology/American Heart Association guidelines for diagnosis and management of hypertension. 2019, Nature Publishing Group.
Allison, M. A. et al. Association between different measures of blood pressure and coronary artery calcium in postmenopausal women. Hypertension 52(5), 833–840 (2008).
Kurioka, S. et al. Risk of progression to hypertension in nonhypertensive Japanese workers aged 20–64 years. J. Hypertens. 32(2), 236–244 (2014).
Lewington, S. Prospective studies collaboration. Age-specific relevance of usual blood pressure to vascular mortality: A meta-analysis of individual data for one million adults in 61 prospective studies. Lancet 360, 1903–1913 (2002).
Bosworth, H. B. et al. Two self-management interventions to improve hypertension control: A randomized trial. Ann. Intern. Med. 151(10), 687–695 (2009).
Group, A.S., Cushman, WC, Evans, GW, Byington, RP, et al. Effects of intensive blood-pressure control in type. 2: p. 1575–1585.
Wright, E. E. et al. Time in range: how to measure it, how to report it, and its practical application in clinical decision-making. Clin. Diabetes 38(5), 439–448 (2020).
Ernst, M. E. et al. Long-term blood pressure variability and risk of cardiovascular disease events among community-dwelling elderly. Hypertension 76(6), 1945–1952 (2020).
de Havenon, A. et al. Blood pressure variability and cardiovascular outcomes in patients with prior stroke: A secondary analysis of PRoFESS. Stroke 50(11), 3170–3176 (2019).
Mezue, K. et al. Blood pressure variability predicts adverse events and cardiovascular outcomes in SPRINT. J. Clin. Hypertens. 20(9), 1247–1252 (2018).
Piercy, K. L. et al. The physical activity guidelines for Americans. JAMA 320(19), 2020–2028 (2018).
Blankstein, R. et al. The implication of coronary artery calcium testing for cardiovascular disease prevention and diabetes. Endocrinol. Metab. 32(1), 47 (2017).
Rahimian, F. et al. Predicting the risk of emergency admission with machine learning: Development and validation using linked electronic health records. PLoS Med. 15(11), e1002695 (2018).
Bayoumy, K. et al. Smart wearable devices in cardiovascular care: where we are and how to move forward. Nat. Rev. Cardiol. 2, 1–19 (2021).
Alghamdi, M. et al. Predicting diabetes mellitus using SMOTE and ensemble machine learning approach: The Henry Ford ExercIse Testing (FIT) project. PLoS ONE 12(7), e0179805 (2017).
Acknowledgements
This work was done as part of the AI Singapore (AISG) Jarvis project collaboration between National University of Singapore (NUS) Institute of Data Science (IDS) and SingHealth Group (SingHealth). This work was funded by National Research Foundation Singapore (Grant: AISG-GC-2019-001).
Author information
Authors and Affiliations
Contributions
W.Y.T. and interpretation and manuscript preparation; W.H.: study conceptualization and design, data interpretation, manuscript preparation, and editing; S.K.N., W.L.C.C., Y.K.K., L.B., O.E.H.M.: study conceptualization and design, manuscript editing, and supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huang, W., Ying, T.W., Chin, W.L.C. et al. Application of ensemble machine learning algorithms on lifestyle factors and wearables for cardiovascular risk prediction. Sci Rep 12, 1033 (2022). https://doi.org/10.1038/s41598-021-04649-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-04649-y
This article is cited by
-
Application of machine learning in measurement of ageing and geriatric diseases: a systematic review
BMC Geriatrics (2023)
-
Artificial Intelligence for Risk Assessment on Primary Prevention of Coronary Artery Disease
Current Cardiovascular Risk Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
