
Abstract
The topology and dynamics of a complex network shape its functionality. However, the topologies of many large-scale networks are either unavailable or incomplete. Without the explicit knowledge of network topology, we show how the data generated from the network dynamics can be utilised to infer the tempo centrality, which is proposed to quantify the influence of nodes in a consensus network. We show that the tempo centrality can be used to construct an accurate estimate of both the propagation rate of influence exerted on consensus networks and the Kirchhoff index of the underlying graph. Moreover, the tempo centrality also encodes the disturbance rejection of nodes in a consensus network. Our findings provide an approach to infer the performance of a consensus network from its temporal data.
Similar content being viewed by others

Introduction
Centrality is designed to identify the most important nodes in a network and has been examined for several decades1,2,3. A node with a larger centrality value is considered more influential in a network4. The network topology plays a paramount role in centrality metrics, for instance, through its degree (the number of connections incident upon a node), eigenvector (based on the idea that connections to high-scored nodes contribute more to the score of the node than connections to low-scored nodes), betweenness (quantifies the number of times a node acts as a bridge along the shortest path between two other nodes), closeness (the reciprocal of the sum of its distances from all other nodes), and k-shell (or k-core of a graph is its maximal connected subgraph in which all nodes have degree at least k), etc. However, the topology of many large-scale networks could be unavailable, incomplete or unreliable. Even when the network topology is known, it might be expensive to compute its centrality index using global information. To this end, we examine whether we can compute the network centrality without the explicit knowledge of network topology and whether each individual node can infer its role from local observations. In addition to the network topology, the dynamics provides an alternative ingredient for identifying the role of nodes in a complex network. Recently, more links between centrality metrics and the network dynamics have been explored, such as in the context of percolation centrality5, control centrality6, and grounding centrality7, etc.
In this paper, we focus on consensus networks, a type of complex network whose components are diffusively coupled, and provide an elegant prototype for collective behaviors such as flocking of birds, schooling of fish, and phase transition in self-propelled agents8. We introduce a novel metric tempo centrality to quantify the influence of nodes in a consensus network, and show that the proposed metric can be computed from the temporal data of the network, even when the network topology is unavailable. An algorithm is subsequently given for the computation of tempo centrality. Moreover, the tempo centrality is shown to have a close correlation with both convergence rate and functional robustness of consensus networks.
Results
Tempo Centrality
Consider a networked system with  nodes depending on the application. Each agent
nodes depending on the application. Each agent  has a state at time t denoted by xi(t) that could represent position, temperature, or opinion. The interaction topology amongst agents is dictated by a graph
has a state at time t denoted by xi(t) that could represent position, temperature, or opinion. The interaction topology amongst agents is dictated by a graph  with a node set
with a node set  , an edge set
, an edge set  , and an adjacency matrix
, and an adjacency matrix  , respectively. The adjacency matrix
, respectively. The adjacency matrix  is such that
is such that  when
when  and
and  otherwise. The networks discussed in this paper are assumed to be simple, undirected and connected9.
otherwise. The networks discussed in this paper are assumed to be simple, undirected and connected9.
We discuss the consensus dynamics

that has been extensively examined in distributed coordination of multi-agent systems10,11,12,13, opinion formation in social networks14,15 and synchronization amongst oscillators16. We shall refer to network adopting consensus dynamics (1) as the consensus network. We say consensus is achieved for a consensus network when  for all
for all  10. The consensus dynamics (1) provides an elegant prototype for the emergence of synchronization17.
10. The consensus dynamics (1) provides an elegant prototype for the emergence of synchronization17.
Controlling a consensus network (steering the states of all the agents to a desired value) can be achieved by influencing a group of agents  and the effect of control depends on the selection of the set
and the effect of control depends on the selection of the set  . In this paper, we are interested in understanding the role of agents in a consensus network when acting as anchors through which the external inputs exert influence on the network.
. In this paper, we are interested in understanding the role of agents in a consensus network when acting as anchors through which the external inputs exert influence on the network.
Denote the set of external inputs as  , where
, where  and i ∈ {1, 2, …, m}. Those agents who are directly influenced by the external inputs are referred to as the leader agents (or informed agents). The set of leader agents is denoted by
and i ∈ {1, 2, …, m}. Those agents who are directly influenced by the external inputs are referred to as the leader agents (or informed agents). The set of leader agents is denoted by  . Denote by
. Denote by  as the influence matrix such that
as the influence matrix such that  if and only if there exists
if and only if there exists  such that the agent
such that the agent  is directly influenced by ul, and
is directly influenced by ul, and  otherwise. It is assumed that each agent can be directly influenced by at most one external input. Thus the sum of each row of
otherwise. It is assumed that each agent can be directly influenced by at most one external input. Thus the sum of each row of  is less than 1 and there exists a one-to-one correspondence between
is less than 1 and there exists a one-to-one correspondence between  and
and  . Denote the influence matrix determined by a node set
. Denote the influence matrix determined by a node set  as
as  . The individual behaviour is thus shifted to the following influenced consensus dynamics as a result of the external input,
. The individual behaviour is thus shifted to the following influenced consensus dynamics as a result of the external input,

The network state, denoted by x (t) = [x1(t), x2(t), …, xn(t)]Τ, characterises the behaviour of the overall system where Τ represents the transpose operation. The dynamics of the network state with external inputs is then

where u = [u1, u2, …, um]Τ,  , and
, and  represents the graph Laplacian or Kirchhoff matrix satisfying
represents the graph Laplacian or Kirchhoff matrix satisfying  for all i = j and
for all i = j and  for all i ≠ j. The complex network with the influenced consensus dynamics (2) is referred to as the influenced consensus network.
for all i ≠ j. The complex network with the influenced consensus dynamics (2) is referred to as the influenced consensus network.
An example of the structure of an influenced consensus network is shown in Supplementary Figure 1, where agent 1 is directly influenced by an external input  and therefore is a leader agent. In this example, the influence matrix is
and therefore is a leader agent. In this example, the influence matrix is

and the corresponding influenced consensus dynamics is

On the one hand, the evolution of the influenced consensus network (3) depends on the type of external inputs. The set of external inputs  is homogeneous if ui = uj for all
is homogeneous if ui = uj for all  and heterogeneous otherwise. If the external inputs are homogeneous, then consensus is achieved on the value of the external input, namely, limt→∞x(t) = ui1 where
and heterogeneous otherwise. If the external inputs are homogeneous, then consensus is achieved on the value of the external input, namely, limt→∞x(t) = ui1 where  and i ∈ {1, 2, …, m}11. Clusters (where the states of agents converge to several distinct values) would emerge when external inputs are heterogeneous18. The results in this paper are available for both homogeneous and heterogeneous inputs. We do assume however that the external inputs are time-invariant which can be considered as the belief of a zealot19 or the opinion of stubborn individuals or political leaders15.
and i ∈ {1, 2, …, m}11. Clusters (where the states of agents converge to several distinct values) would emerge when external inputs are heterogeneous18. The results in this paper are available for both homogeneous and heterogeneous inputs. We do assume however that the external inputs are time-invariant which can be considered as the belief of a zealot19 or the opinion of stubborn individuals or political leaders15.
On the other hand, the dynamics of the influenced consensus network is also shaped by the influence matrix  . Note that
. Note that  is a diagonal matrix with only ii-th entry 1 where
is a diagonal matrix with only ii-th entry 1 where  , and 0 for other entries. The matrix
, and 0 for other entries. The matrix  is then derived from the perturbation of the graph Laplacian by the diagonal matrix
is then derived from the perturbation of the graph Laplacian by the diagonal matrix  ; it is therefore referred to as the perturbed Laplacian matrix. The perturbed graph Laplacian of an undirected graph is symmetric; hence we denote the eigenvalues of
; it is therefore referred to as the perturbed Laplacian matrix. The perturbed graph Laplacian of an undirected graph is symmetric; hence we denote the eigenvalues of  as 0 < λ1 < λ2 ≤ … ≤ λn and the corresponding normalised eigenvectors as v1, v2, …, vn. In essence, the spectra of
as 0 < λ1 < λ2 ≤ … ≤ λn and the corresponding normalised eigenvectors as v1, v2, …, vn. In essence, the spectra of  dictates the evolution of influenced consensus dynamics (3).
dictates the evolution of influenced consensus dynamics (3).
Controlling a consensus network via different leader agents impacts the network differently. The influence of an agent (or a group of agents) in a consensus network can be measured by the fluctuation of the network state x (t) triggered by this agent(s). We shall characterise the state fluctuation by a differentiation operator.
Taking the influenced consensus network in Supplementary Figure 1 as an example, we use quantity

to characterise the influence of leader agent 1, where ||⋅||2 represents the Euclidean vector norm. The state evolution of each agent and r{1}(t) are shown in Fig. 1(a) and (b), respectively. The time window can be divided into two stages according to the convergence of r{1}(t), denoted by the coherence stage and the tracking stage, respectively. During the coherence stage, agents aggregate their states under the attractive force generated by diffusive couplings amongst agents. Since the consensus network is influenced by an external input u = 10, all agents subsequently track the external input via the leader agents. The two panels are both divided by the green dashed vertical lines at the time step t ≈ 4.5, on which r{1}(t) has converged to a steady value of 0.328. The coherence stage is governed by all the eigenvalues of  and the corresponding eigenvectors, but the tracking stage is dominated by λ1 and v1. According to the Perron– Frobenius theorem, the entries of v1 are all nonzero and can be selected to be positive20.
and the corresponding eigenvectors, but the tracking stage is dominated by λ1 and v1. According to the Perron– Frobenius theorem, the entries of v1 are all nonzero and can be selected to be positive20.

(a) The trajectories of agents’ states of the influenced consensus network in Supplementary Figure 1 and (b) the trajectory of r{1}(t).
For a set of agents  , we define its tempo centrality (TC), denoted by
, we define its tempo centrality (TC), denoted by  , as
, as  , where v1 is the normalised eigenvector corresponding to the smallest eigenvalue of
, where v1 is the normalised eigenvector corresponding to the smallest eigenvalue of  ,
,  , and
, and  denotes the column vector with 1 for the ij-th entry and 0 otherwise, where j ∈ {1, 2, …, s}. It has been shown in ref. 21 that the long-term behaviour of
denotes the column vector with 1 for the ij-th entry and 0 otherwise, where j ∈ {1, 2, …, s}. It has been shown in ref. 21 that the long-term behaviour of

is determined by v1, namely,

implying that  is independent of both the initial state x (0) and the external input u , as shown in Supplementary Figs 2 and 3. Note that TC takes values from entries of a positive normalised eigenvector, therefore
is independent of both the initial state x (0) and the external input u , as shown in Supplementary Figs 2 and 3. Note that TC takes values from entries of a positive normalised eigenvector, therefore  . The TC characterises the tempo of agents with respect to that of the entire network in the tracking stage when they act as leaders.
. The TC characterises the tempo of agents with respect to that of the entire network in the tracking stage when they act as leaders.
Computation of TC based on Temporal Data
The evolution of the network state is dictated by the network topology and the individual node dynamics. According to (5), the network snapshots that are generated by the individual dynamics can provide an alternative way for the computation of TC even when the network topology is unknown. We shall utilize this property for the design of an algorithm for computing TC from the temporal data of a consensus network.
Consider a consensus network with the set of leader agent  and the corresponding perturbed Laplacian matrix
and the corresponding perturbed Laplacian matrix  . Denote by hi and hj as selection matrices for the leader agent {i} and a distinct agent {j}, respectively. The following result has been established linking the network state and the spectra of perturbed Laplacian matrix in ref. 21,
. Denote by hi and hj as selection matrices for the leader agent {i} and a distinct agent {j}, respectively. The following result has been established linking the network state and the spectra of perturbed Laplacian matrix in ref. 21,

where v1 is the normalized eigenvector corresponding to the smallest eigenvalue of  .
.
We now show how TC can be computed from the network snapshots. Without loss of generality, designate agent 1 as the leader agent in the network, i.e.,  . Discretizing (3) at the sampling points t0 ≤ δ1 < δ2 < … < δm yields an m-length snapshots of the consensus network, i.e.,
. Discretizing (3) at the sampling points t0 ≤ δ1 < δ2 < … < δm yields an m-length snapshots of the consensus network, i.e.,  where t0 ≥ 0 is the initial time step and k = 0, 1, …, m. Denote
where t0 ≥ 0 is the initial time step and k = 0, 1, …, m. Denote  satisfying
satisfying


where

Then, it follows that

According to the definition, the first entry of  approaches the TC of agent 1 when k → ∞. A value threshold ε > 0 needs to be set such that the computation of
approaches the TC of agent 1 when k → ∞. A value threshold ε > 0 needs to be set such that the computation of  terminates when reaching its steady state. The above discussions conclude the following algorithm that computes the TC of leader agent 1.
terminates when reaching its steady state. The above discussions conclude the following algorithm that computes the TC of leader agent 1.

The complexity of Algorithm 1 depends on the convergence of r{i},{j}(k) for all  , which is controlled by the ε. As a result, the computation complexity of Algorithm 1 is
, which is controlled by the ε. As a result, the computation complexity of Algorithm 1 is  where n is the network size and ω(ε) denotes the total number of steps after which r{i},{j}(k) converges to its steady state with an accuracy of ε. Note that
where n is the network size and ω(ε) denotes the total number of steps after which r{i},{j}(k) converges to its steady state with an accuracy of ε. Note that  is a global information for a given influence structure and is usually not accessible to the agents in the network. However, according to (6), each agent can still infer the relative role of nodes via local measurements.
is a global information for a given influence structure and is usually not accessible to the agents in the network. However, according to (6), each agent can still infer the relative role of nodes via local measurements.
Here, we proceed to discuss the amount of data needed for the implementation of Algorithm 1. Theoretically, we have

We thereby quantify the error of estimating v1 with an m-length network snapshots  by
by

where

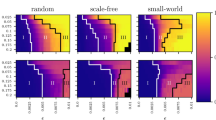
The smaller the value of ψ the more accurate the estimation of v1 with network snapshots. Intuitively, more data will improve the estimation accuracy. Figure 2(a) and (b) show the estimation error ψ is decreasing when more snapshots are used in an ER random network and a scale-free network. In fact, we can start sampling the network state x(t), over a time interval of t ∈ [t1, t2], from t1 in a forward sequence (forward sampling), or from t2 in a reversed sequence (backward sampling). The backward sampling is more preferable since  is closer to its steady state. In Fig. 2(c) and (d), we apply the backward sampling and the estimation error ψ is shown to be dramatically decreased compared with the forward sampling. In the backward sampling, it turns out that the length of snapshots m has little influence on the estimation error ψ. The two methods mentioned above sample x(t) with respect to time t uniformly, which is somewhat difficult to achieve due to the disturbance in measurement. We subsequently examine the performance of random sampling of x(t), namely, selecting at most m snapshots randomly. Figure 2(e) and (f) show that the performance of random sampling and the length of snapshots m also has little influence on the improvement of estimation accuracy in this scenario (for instance, in ER random networks, the estimation error obtained from m = 5 snapshots in random sampling is better than that from m = 300 in a forward sampling, as shown in Fig. 2(a) and (e)). We now show the influence of initial point of sampling δ1 on ψ in Fig. 3. It turns out that the later the sampling process starts the more accurate the effect of estimation. Supplementary Figures 16, 17 and 18 show this trend in more networks. Therefore, the initial point of sampling is a critical factor. As a result, we can conclude that (a) the careful selection of sampling points is critical in the efficiency of Algorithm 1, (b) the length of snapshots can be as short as m = 2 (in order to make the computation of (8) feasible) and (c) the sampling points can be heterogeneously distributed over the time interval.
is closer to its steady state. In Fig. 2(c) and (d), we apply the backward sampling and the estimation error ψ is shown to be dramatically decreased compared with the forward sampling. In the backward sampling, it turns out that the length of snapshots m has little influence on the estimation error ψ. The two methods mentioned above sample x(t) with respect to time t uniformly, which is somewhat difficult to achieve due to the disturbance in measurement. We subsequently examine the performance of random sampling of x(t), namely, selecting at most m snapshots randomly. Figure 2(e) and (f) show that the performance of random sampling and the length of snapshots m also has little influence on the improvement of estimation accuracy in this scenario (for instance, in ER random networks, the estimation error obtained from m = 5 snapshots in random sampling is better than that from m = 300 in a forward sampling, as shown in Fig. 2(a) and (e)). We now show the influence of initial point of sampling δ1 on ψ in Fig. 3. It turns out that the later the sampling process starts the more accurate the effect of estimation. Supplementary Figures 16, 17 and 18 show this trend in more networks. Therefore, the initial point of sampling is a critical factor. As a result, we can conclude that (a) the careful selection of sampling points is critical in the efficiency of Algorithm 1, (b) the length of snapshots can be as short as m = 2 (in order to make the computation of (8) feasible) and (c) the sampling points can be heterogeneously distributed over the time interval.

The error bar is plotted with 500 realizations for each network type and one leader is randomly selected for each such realizations. The edge occurrence probability for ER random networks is 0.05. In random sampling, at most m of snapshots are selected.

Error bar plot of the influence of initial point of sampling on ψ in 100-node ER random networks (ER) with forward sampling (a) and random sampling (b); and scale-free (SF) networks with forward sampling (c) and random sampling (d). A consecutive 20 snapshots from δ1 have been selected. 500 realizations are used for each type of network.
Correlation with Network Performance
In this section, we proceed to explore the correlation between TC and two network performance metrics, namely, the convergence rate of consensus and the network robustness, both of which are closely related to the spectra of  7,21. Since TC is derived from the normalised eigenvector of the perturbed Laplacian matrix, there are analytic connections between TC and network performances that are determined by the spectra of
7,21. Since TC is derived from the normalised eigenvector of the perturbed Laplacian matrix, there are analytic connections between TC and network performances that are determined by the spectra of  . However, one can compute TC based on network snapshots and thus the related network performances can be estimated with a data-driven approach.
. However, one can compute TC based on network snapshots and thus the related network performances can be estimated with a data-driven approach.
Convergence Rate of Consensus
The smallest eigenvalue of  (denoted by λ1 in our discussion) provides us with the convergence rate of the consensus network influenced by the external input, on the other hand, λ1 reflects how fast the diffusion of the external input (friendly or malicious, deterministic or stochastic) proceeds on the network7,22. Therefore, λ1 can be regarded as a measure of spreading power of nodes in a consensus network from the perspective of the propagation efficiency of external inputs (refer to section 1 in Supplementary Information for details). Here, we provide some analytical facts between TC and λ1. For an arbitrary agent
(denoted by λ1 in our discussion) provides us with the convergence rate of the consensus network influenced by the external input, on the other hand, λ1 reflects how fast the diffusion of the external input (friendly or malicious, deterministic or stochastic) proceeds on the network7,22. Therefore, λ1 can be regarded as a measure of spreading power of nodes in a consensus network from the perspective of the propagation efficiency of external inputs (refer to section 1 in Supplementary Information for details). Here, we provide some analytical facts between TC and λ1. For an arbitrary agent  with the corresponding selection matrix h and influence matrix
with the corresponding selection matrix h and influence matrix  , starting from
, starting from

and multiplying (9) by 1T from left on both sides yields

Since the entries of v1 can be chosen to have the same signs,

where  represents the 1-norm of vectors.
represents the 1-norm of vectors.
Note that v1 is normalised in terms of the 2-norm of vectors, i.e.,  . According to the equivalency of vector norms, we have
. According to the equivalency of vector norms, we have

which implies the propagation efficiency λ1 is lower bounded by  . Figure 4(a,c) and Supplementary Table 3 show that λ1 can be well-approximated by
. Figure 4(a,c) and Supplementary Table 3 show that λ1 can be well-approximated by  in ER random networks, scale-free networks and many empirical networks. The error bar of approximation errors in Fig. 4 reflects that the approximation effect is improved in large and dense networks. However, as shown in Supplementary Figures 19(a) and (c), the maximum relative errors corresponding to large sparse networks still imply an accurate estimation of λ1 with TC. We proceed to use Pearson correlation analysis to show that there is a strong linear correlation between TC and λ1. The Pearson coefficient between TC and λ1 in an 500-node Erdős-Rényi (ER) random network and a 500-node scale-free network (SF) is shown in Fig. 5(a,b). The Pearson coefficients (PC) are 1 and 0.99943 for ER random network and scale-free network, respectively, implying the total positive correlation between TC and λ1.
in ER random networks, scale-free networks and many empirical networks. The error bar of approximation errors in Fig. 4 reflects that the approximation effect is improved in large and dense networks. However, as shown in Supplementary Figures 19(a) and (c), the maximum relative errors corresponding to large sparse networks still imply an accurate estimation of λ1 with TC. We proceed to use Pearson correlation analysis to show that there is a strong linear correlation between TC and λ1. The Pearson coefficient between TC and λ1 in an 500-node Erdős-Rényi (ER) random network and a 500-node scale-free network (SF) is shown in Fig. 5(a,b). The Pearson coefficients (PC) are 1 and 0.99943 for ER random network and scale-free network, respectively, implying the total positive correlation between TC and λ1.

The error of approximating λ1 by  in ER random networks (a) and scale-free networks (c); the error of approximating Kirchhoff index by
in ER random networks (a) and scale-free networks (c); the error of approximating Kirchhoff index by  in ER random networks (b) and scale-free networks (d). The possibility for edge occurrence p ranges from 0.1 to 1 at the regular interval 0.1 (the plot for p = 0.05 to p = 0.1 is shown in Supplementary Figure 19). For each realization of the network, we compute the TC for all nodes
in ER random networks (b) and scale-free networks (d). The possibility for edge occurrence p ranges from 0.1 to 1 at the regular interval 0.1 (the plot for p = 0.05 to p = 0.1 is shown in Supplementary Figure 19). For each realization of the network, we compute the TC for all nodes  in the network and the corresponding
in the network and the corresponding  . Since the Kirchhoff index corresponds to the entire network, we only need to compute the Kirchhoff index for each realization of the network and its approximation by TC. 500 realizations are used for each type of network.
. Since the Kirchhoff index corresponds to the entire network, we only need to compute the Kirchhoff index for each realization of the network and its approximation by TC. 500 realizations are used for each type of network.

The TC as a function of λ1 in an Erdős-Rényi (ER) random network (a) and a scale-free network (SF) (b). The Pearson coefficient between TC and λ1 are 1 (ER) and 0.99948 (SF), respectively. The TC as a function of resistance distance (RD) in an Erdős-Rényi (ER) random network (c) and a scale-free network (SF) (d). The Pearson coefficient between TC and RD are −0.99989 (ER) and −0.91839 (SF), respectively.
Kirchhoff Index and Network Robustness
Viewing each edge in the network as a one-Ohm resistor, the effective resistance from the leader agents to all agents in the network is shown to be an index of network robustness from the perspective of both the  system norm (ability of disturbance rejection in the presence of additive noise in consensus networks)23,24 and the vulnerability of the network connectivity to node or edge failures23,24,25. The perturbed Laplacian matrix turns out to be an important construct that is closely related to the effective resistance. Specifically, the
system norm (ability of disturbance rejection in the presence of additive noise in consensus networks)23,24 and the vulnerability of the network connectivity to node or edge failures23,24,25. The perturbed Laplacian matrix turns out to be an important construct that is closely related to the effective resistance. Specifically, the  measures the functional robustness of the influenced consensus network in terms of the variance of deviation from consensus and the disturbance rejection properties of consensus networks, both of which can be characterised by the effective resistance of the network22,26,27,28,29. The structural robustness of complex networks has also been widely investigated in the context of percolation theory30,31.
measures the functional robustness of the influenced consensus network in terms of the variance of deviation from consensus and the disturbance rejection properties of consensus networks, both of which can be characterised by the effective resistance of the network22,26,27,28,29. The structural robustness of complex networks has also been widely investigated in the context of percolation theory30,31.
The resistance distance from agents i to j, denoted by dij, is the effective resistance between i and j, which can be quantified by the diagonal entries of  24,32. Suppose that the network is influenced by a single external input via agent
24,32. Suppose that the network is influenced by a single external input via agent  and denote the resultant perturbed Laplacian matrix as
and denote the resultant perturbed Laplacian matrix as  , which is invertible if
, which is invertible if  is connected32. The resistance distance from input u to agent
is connected32. The resistance distance from input u to agent  is
is  22,32, and thus the resistance distance from the agent i to agent j is such that
22,32, and thus the resistance distance from the agent i to agent j is such that  . Hence, the resistance distance from agent i to all agents in
. Hence, the resistance distance from agent i to all agents in  , denoted by qi, is the summation of dij over all
, denoted by qi, is the summation of dij over all  , i.e.,
, i.e.,

In the following discussion, we shall refer to qi as the resistance distance (RD) index of  . The Kirchhoff index of a network
. The Kirchhoff index of a network  (introduced by Klein and Randic′ in ref. 24) is half of the total effective resistance between all pair of nodes in
(introduced by Klein and Randic′ in ref. 24) is half of the total effective resistance between all pair of nodes in  and can therefore be computed by
and can therefore be computed by

Kirchhoff index is a measure of connectivity and size of a network in terms of resistance distance23. A network with smaller value of Kirchhoff index is considered to be more robust to node or edge failures. Kirchhoff index is also related to the average power dissipation of the circuit with a random current excitation and the average commute time of a Markov chain on a graph. Algorithms have also been proposed for minimizing the Kirchhoff index a network33.
The smallest eigenvalue of the perturbed Laplacian matrix can be considered as the perturbation of the smallest eigenvalue of the Laplacian matrix, which is always zero. The influence of this perturbation decreases when the network size grows, and consequently the term  would dominate qi in (13). Based on the estimation of
would dominate qi in (13). Based on the estimation of  , we can further approximate qi by
, we can further approximate qi by

and the Kirchhoff index by

Figure 4(b) and (d) and Supplementary Table 3 show the effect of this approximation in ER random networks, scale-free networks, and empirical networks. The maximum relative errors shown in Supplementary Figures 19(c) and 19(d) corresponding to large sparse networks still imply a good estimation of Kirchhoff index with TC. The Pearson coefficient between TC and resistance distance in 500-node Erdős-Rényi (ER) random network and 500-node scale-free network is shown in Fig. 5(c) and (d). The Pearson coefficients (PC) are −0.99988 and −0.91485 for the ER random network and the scale-free network (both implying the strong negative correlations). We have shown the results of Pearson correlation analysis and the corresponding regression coefficient in Supplementary Tables 1 and 2 for all 7 metrics mentioned in this paper under ER random networks, scale-free networks, and empirical networks. It has been shown that there exist a total positive correlation between TC and λ1, and a strong negative correlation between TC and resistance distance for different classes of networks, enabling us to estimate these network performance metrics from network snapshots. The robustness of nodes in terms of centrality attack is shown in Fig. 6 and Supplementary Figures 21 and 22.
 as a function of the fraction of removed nodes f for centrality metrics including TC, degree, betweenness, closeness and k-shell.
as a function of the fraction of removed nodes f for centrality metrics including TC, degree, betweenness, closeness and k-shell.
(a) The ER random (ER) network with n = 500 and p = 0.05, (b) the scale-free (SF) network with n = 100 and 〈η〉 = 0.02, (c) the Karate club network with n = 34, and (d) the IEEE 118 bus system network with n = 118. The error bar plots for ER and SF are over 500 realizations for each network type.
Zachary’s Karate Club
As a case study, we have applied TC to quantify the role of members in the Zachary’s Karate club34. In this case, TC highlights the president (node 1) and lesson instructor (node 34) in the club by assigning the top two largest TC values to them. The rank of each node in the network in terms of the value of TC, degree, eigenvector, betweenness, closeness and k-shell is shown in Table 1. We compute the Spearman’s rank correlation coefficient (the Pearson correlation between the rank values of two variables) between TC and degree, eigenvector, betweenness, closeness and k-shell, respectively. TC is shown closer to the degree (with Spearman’s rank correlation coefficient as 0.9422) in this example, followed by closeness (0.9251), betweenness (0.9013), eigenvector (0.8597) and k-shell (0.8481). We subsequently compared the TC with above five centrality metrics in the Karate club network by normalising the values of these centrality metrics as illustrated in Supplementary Figure 4. The distribution of the TC values in the heat map is shown in Fig. 7. According to the pattern of the normalised centrality values, TC identifies the distinct role of nodes compared with the other five centrality metrics in this example. The scatter plots and Pearson coefficient between TC and seven other metrics (above five centralities plus λ1 and RD) in Karate club network are shown in Supplementary Figures 5 and 6 respectively. More scatter plots are shown in Supplementary Figures 7–15 for 9 empirical networks.

The size of dots are proportional to their TC value. The top two largest TC values are achieved for agent 34 and agent 1 (0.1569 and 0.1561, respectively).
Discussion
Instead of quantifying the importance of a single agent in the network, the importance of a group of agents can also be characterised by TC, which is meaningful when the group is considered as in union or multiple leader agents are needed to exert influence on a consensus network. For a given group of leader agents, the larger the value of TC the faster the external influence propagates throughout the network and the less resistance the external influence has to overcome. In the meanwhile, the larger TC implies that the leader agent related to the influence matrix evolves towards the external input with a faster tempo than the rest of the network. Note that the influence of a single agent decreases when the network size grows; as a result, more leader agents are needed to exert a stronger influence.
Topology identification (through such methods as compressive sensing, linear system identification, power spectral analysis, convex programming etc.) is generally based on the minimization of the distance between the estimated and the real network structures. Therefore, the entry-wise errors are acceptable for the optimization procedure. However, the role of an individual node can be different with respect to an entry-wise error, even when the two estimated network structures are equivalent from an optimization perspective. Our data-driven approach is robust to this ambiguity.
The second smallest eigenvalue of the graph Laplacian is known as the algebraic connectivity of a network, characterising the convergence rate of the consensus process10,35; and the corresponding eigenvector, called the Fiedler vector, has been widely applied in the network partitioning35. We can regard all agents in a network  along with the set of external input
along with the set of external input  as an expanded directed graph, in which the directed edges are present only from the external input to the leader agents. The vector
as an expanded directed graph, in which the directed edges are present only from the external input to the leader agents. The vector  can be considered as the Fiedler vector for this expanded digraph, where 0m×1 denotes the m × 1 vector with all zero entries. The impact of the external input on the network
can be considered as the Fiedler vector for this expanded digraph, where 0m×1 denotes the m × 1 vector with all zero entries. The impact of the external input on the network  can be characterised by the spectra of
can be characterised by the spectra of  . Using the spectral decomposition of the perturbed Laplacian matrix, i.e.,
. Using the spectral decomposition of the perturbed Laplacian matrix, i.e.,  , we observe that the eigenvector v1 shapes the behaviour of the network when the dynamics in directions of v2, v3 …, vn vanish. As one can see from Supplementary Figure 20, that the distribution of entries in v1 is shaped by the placement of the leader agent, that is, the farther a node is from the leader agent, the larger the absolute value of its corresponding entry in v1.
, we observe that the eigenvector v1 shapes the behaviour of the network when the dynamics in directions of v2, v3 …, vn vanish. As one can see from Supplementary Figure 20, that the distribution of entries in v1 is shaped by the placement of the leader agent, that is, the farther a node is from the leader agent, the larger the absolute value of its corresponding entry in v1.
A summary of the utility of TC and our proposed approach is as follows. The TC is shown to be closely correlated to two performance metrics for consensus networks, namely, the convergence rate of the influenced consensus (characterising the propagation efficiency of the external influence over a consensus network) and the network functional robustness in terms of disturbance rejection; the TC can be computed from the network snapshots even when the network topology is unknown; the data-driven approach in this paper enables each agent to determine its relative role in the network by using the state of its neighbors; this relative role obtained by each agent via local information is a global information; since the linearization of the Kuramoto dynamics around the origin is consensus dynamics the results discussed in this paper have a natural extension to the Kuramoto model, widely investigated for oscillator networks36.
Methods
Normalization of Centrality
The centrality vector c = [c1, c2, …, cn]Τ of a network  is composed of the centrality value ci of all nodes
is composed of the centrality value ci of all nodes  in
in  . Since the value of centrality could differ in scale, we normalize ci to the interval [0, 1] by the maximum value of a given centrality as follows
. Since the value of centrality could differ in scale, we normalize ci to the interval [0, 1] by the maximum value of a given centrality as follows

Pearson Correlation Coefficient
The Pearson correlation coefficient for two vectors  and
and  is defined as
is defined as

Relative Error
The approximation error is measured by the relative error between vectors. Let  be an approximation of vector
be an approximation of vector  . The relative error used in this paper is,
. The relative error used in this paper is,

Edge Density
The edge density of a network  is defined as the ratio between the number of edges and the maximum number of possible edges in a network, i.e.,
is defined as the ratio between the number of edges and the maximum number of possible edges in a network, i.e.,

Error Bar
The error bar plots in this paper represent the fluctuation of data around their respective mean. The marker in the centre of an error bar represents the mean of the data; the upper and lower intervals represent the deviation of the mean from the maximum and minimum value of the data.
Centrality Attack
In the centrality attack, the nodes in a network are sorted in descending order according to their centrality value, then the first f ∈ (0, 1] fraction of nodes are removed from the network. The normalized size of largest connected component  is used to quantify the effect of the attack.
is used to quantify the effect of the attack.
Networks
An n-node Erdős-Rényi (ER) random network with the probability of edge realization p ∈ [0, 1] is denoted by  and is constructed by randomGraph.m in Octave routines for network analysis37. The scale-free network with degree distribution p(k) ~ k−γ is generated by SFNG.m in B-A Scale-Free Network Generation and Visualization38. The empirical networks are from KONECT39. The centrality value of the network degree, eigenvector, betweenness and closeness are computed using Octave routines for network analysis37. The k-shell is computed by corenums.m in Graph Algorithms In Matlab Code (gaimc)40.
and is constructed by randomGraph.m in Octave routines for network analysis37. The scale-free network with degree distribution p(k) ~ k−γ is generated by SFNG.m in B-A Scale-Free Network Generation and Visualization38. The empirical networks are from KONECT39. The centrality value of the network degree, eigenvector, betweenness and closeness are computed using Octave routines for network analysis37. The k-shell is computed by corenums.m in Graph Algorithms In Matlab Code (gaimc)40.
Additional Information
How to cite this article: Shao, H. et al. Inferring Centrality from Network Snapshots. Sci. Rep. 7, 40642; doi: 10.1038/srep40642 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Freeman, L. C. Centrality in social networks conceptual clarification. Social Networks 1, 215–239 (1979).
Borgatti, S. P. Centrality and network flow. Social Networks 27, 55–71 (2005).
Borgatti, S. P. & Everett, M. G. A graph-theoretic perspective on centrality. Social Networks 28, 466–484 (2006).
Sabidussi, G. The centrality index of a graph. Psychometrika 31, 581–603 (1966).
Piraveenan, M., Prokopenko, M. & Hossain, L. Percolation centrality: Quantifying graph-theoretic impact of nodes during percolation in networks. PloS ONE 8, e53095 (2013).
Liu, Y., Slotine, J. & Barabási, A. Control centrality and hierarchical structure in complex networks. PloS ONE 7, e44459–e44459 (2011).
Pirani, M. & Sundaram, S. On the smallest eigenvalue of grounded laplacian matrices. IEEE Transactions on Automatic Control 61, 509–514 (2016).
Vicsek, T., Czirók, A., Ben-Jacob, E., Cohen, I. & Shochet, O. Novel type of phase transition in a system of self-driven particles. Physical review letters 75, 1226 (1995).
Godsil, C. & Royle, G. F. Algebraic graph theory (Springer Science & Business Media, 2013).
Olfati-Saber, R. & Murray, R. M. Consensus problems in networks of agents with switching topology and time-delays. IEEE Transactions on Automatic Control 49, 1520–1533 (2004).
Jadbabaie, A., Lin, J. & Morse, A. S. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Transactions on Automatic Control 48, 988–1001 (2003).
DeGroot, M. H. Reaching a consensus. Journal of the American Statistical Association 69, 118–121 (1974).
Mesbahi, M. & Egerstedt, M. Graph theoretic methods in multiagent networks (Princeton University Press, 2010).
Lorenz, J. Continuous opinion dynamics under bounded confidence: A survey. International Journal of Modern Physics C 18, 1819–1838 (2007).
Acemoglu, D., Como, G., Fagnani, F. & Ozdaglar, A. Opinion fluctuations and disagreement in social networks. Mathematics of Operations Research 38, 1–27 (2013).
Fell, J. & Axmacher, N. The role of phase synchronization in memory processes. Nature Reviews Neuroscience 12, 105–118 (2011).
Strogatz, S. SYNC: The emerging science of spontaneous order (Hyperion, 2003).
Shao, H., Xi, Y. & Mesbahi, M. On the degree of synchrony. In Proceedings of 54th IEEE Conference on Decision and Control (CDC), 986–991 (IEEE, 2015).
Mobilia, M. Does a single zealot affect an infinite group of voters ? Physical Review Letters 91, 028701 (2003).
Horn, R. A. & Johnson, C. R. Matrix analysis (Cambridge University Press, 2012).
Shao, H. & Mesbahi, M. Degree of relative influence for consensus-type networks. In Proceedings of 2014 American Control Conference, 2676–2681 (IEEE, 2014).
Chapman, A. & Mesbahi, M. Semi-autonomous consensus: Network measures and adaptive trees. IEEE Transactions on Automatic Control 58, 19–31 (2013).
Ellens, W., Spieksma, F., Van Mieghem, P., Jamakovic, A. & Kooij, R. Effective graph resistance. Linear Algebra and Its Applications 435, 2491–2506 (2011).
Klein, D. J. & Randić, M. Resistance distance. Journal of Mathematical Chemistry 12, 81–95 (1993).
Abbas, W. & Egerstedt, M. Robust graph topologies for networked systems. In Proceedings of the 3rd IFAC Workshop on Distributed Estimation and Control in Networked Systems 3, 85–90 (2012).
Lin, F., Fardad, M. & Jovanovic, M. R. Algorithms for leader selection in stochastically forced consensus networks. IEEE Transactions on Automatic Control 59, 1789–1802 (2014).
Bamieh, B., Jovanovic, M., Mitra, P. & Patterson, S. Coherence in large-scale networks: Dimension-dependent limitations of local feedback. IEEE Transactions on Automatic Control 57, 2235–2249 (2012).
Lovisari, E., Garin, F. & Zampieri, S. Resistance-based performance analysis of the consensus algorithm over geometric graphs. SIAM Journal on Control and Optimization 51, 3918–3945 (2013).
Clark, A., Bushnell, L. & Poovendran, R. A supermodular optimization framework for leader selection under link noise in linear multi-agent systems. IEEE Transactions on Automatic Control 59, 283–296 (2014).
Cohen, R. & Havlin, S. Complex networks: structure, robustness and function (Cambridge University Press, 2010).
Albert, R., Jeong, H. & Barabási, A.-L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Barooah, P. & Hespanha, J. P. Graph effective resistance and distributed control: Spectral properties and applications. In Proceedings of the 45th IEEE Conference on Decision and Control, 3479–3485 (IEEE, 2006).
Ghosh, A., Boyd, S. & Saberi, A. Minimizing effective resistance of a graph. SIAM Review 50, 37–66 (2008).
Zachary, W. W. An information flow model for conflict and fission in small groups. Journal of Anthropological Research 452–473 (1977).
Fiedler, M. Algebraic connectivity of graphs. Czechoslovak Mathematical Journal 23, 298–305 (1973).
Acebrón, J. A., Bonilla, L. L., Vicente, C. J. P., Ritort, F. & Spigler, R. The kuramoto model: A simple paradigm for synchronization phenomena. Reviews of Modern Physics 77, 137 (2005).
Bounova, G. Octave networks toolbox (2015). https://doi.org/10.5281/zenodo.22398.
George, M. Ba scale-free network generation and visualization. Matlab Central 12 (2006).
Kunegis, J. Konect: the koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, 1343–1350 (ACM, 2013).
Gleich, D. gaimc: graph algorithms in matlab code. Matlab Toolbox. Matlab (2009).
Acknowledgements
The work of H.S., D.L., and Y.X. has been supported by the National Science Foundation of China (Grant Nos 61333009, 61433002, 61521063, 61590924, 71361130012) and National Program on Key Basic Research Project of China (973 Program, Grant No. 2014CB249200). The work of M.M. has been supported by the National Science Foundation of U.S.A. (Grant No. SES-1541025). We thank anonymous reviewers for the constructive suggestions on this paper.
Author information
Authors and Affiliations
Contributions
M.M. and Y.X. envisioned the research. M.M., Y.X. and H.S. discussed the main points of the manuscript. H.S. implemented the theoretical analysis. H.S. and D.L. designed the numerical simulation and analysed the result. H.S. wrote the manuscript. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Shao, H., Mesbahi, M., Li, D. et al. Inferring Centrality from Network Snapshots. Sci Rep 7, 40642 (2017). https://doi.org/10.1038/srep40642
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep40642
This article is cited by
-
Global temporal dynamic landscape of pathogen-mediated subversion of Arabidopsis innate immunity
Scientific Reports (2017)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
